
INSIGHTS Research
By Sofia Kellogg, 6/09/2021
If you asked me four months ago, ‘What is unsupervised learning and how do we use it to train Machine Learning (“ML”) models?’ I would have given you a blank stare. My background is in political science and sustainability, with a general knowledge about AI. When I say general knowledge, this is what I pictured when I thought about AI:

During my first few weeks, I spoke to the AI Researchers and Engineers on our team to gain a better understanding of exactly what AI is and how we’re using it in the Arabesque AI Engine. Thanks to their guidance, I now understand how our AI Engine works (at a very high level – I am still by no means an expert). If you need help demystifying the AI Engine, continue reading and hopefully this will help you on your journey.
What is AI?
To start, what is AI? Artificial intelligence is a program with the ability to learn and reason like a human. Machine Learning (ML) is a subset of AI. ML is when an algorithm has the ability to learn by itself given some sort of input of data. An algorithm is a set of instructions that a computer program runs. Algorithms take in inputs and spit out outputs.
What is the Arabesque AI Engine?
The Arabesque AI Engine is a group of ML models that take in financial and non-financial data and work together to attempt to analyse patterns and behaviours in equity markets. In this process, the AI Engine can analyse significantly more data than one human could. It is designed to provide an unbiased analysis of a vast amount of data, and to extract potentially unique conclusions from that data. It also significantly reduces the complexity of the data, which creates a more scalable process. We use a combination of supervised and unsupervised learning, incorporating financial data and other inputs, to analyse the probability of the price of a stock going up or down in the future.
AI Engine Inputs
The AI Engine takes in data and outputs the signals (the price predictions) that we use in portfolio construction. We input a variety of financial and non-financial data into the Engine. For example, we look at price returns, net profit, earnings per share, and indices such as the S&P 500. For our input data, we need at least 10 years of all data history in order to make predictions. Additionally, we input non-financial data, such as news and media (via Natural Language Processing (“NLP”) methods) and ESG data from our sister company, Arabesque S-Ray®. All of this data is treated equally by the algorithms, and models learn to choose which ones are most relevant for the universe of the given asset. For each asset we want to analyse, the Engine predicts the probability of whether the price of an asset goes up or down relative to the relevant benchmark index.

Supervised Learning
Supervised learning is when a program takes an input and learns to assign it an output, which is known a priori. Feedback loops help to adjust a model’s output. To do this, we give a ML algorithm a bunch of labelled data that is used as a training example. One caveat: data can still be biased. If I train a model to classify cats and dogs but 99% of the pictures I feed the model are dogs, then the model will have a bias towards dogs. We have to make sure we feed the model relevant information. Below is an example of classification using supervised learning. We feed the algorithm labelled pictures of dogs and cats, which it then uses to categorise animals and give them corresponding labels

The algorithm learns a ML model from this data, and then to test the model, we give it an input it’s never seen before (like an unlabelled picture of a dog) to see if it sorts the new data appropriately and gives a correct output.

If the model does not sort the new data appropriately, we continue to try to improve the algorithm, typically through more training or training on a more diverse dataset (e.g. labradors, spaniels, as well as poodles). The problem with supervised learning is that there can be issues around human error or rare occurrences (i.e. we load one picture of a labrador but this is tagged as a spaniel). It can also take a long time to label all the data we need (although in this case, we would see a lot of cute dog photos which some of our team members wouldn’t mind at all).
Unsupervised Learning
Unsupervised learning is when a computer program must find structure in the input data because it is unlabelled. There are different types of unsupervised learning, such as clustering, reinforcement learning, dimensionality reduction, etc. The example below demonstrates clustering, in which we give the ML algorithm a set of inputs, the algorithm finds similarities between these inputs, and the ML model learns to group these inputs together. In the AI Engine, we have hundreds of input features, and we have to try to condense these data points. We use unsupervised learning to compress the input data.

Lifecycle of a ML Model
It is important to note that training a ML model is not a one-time process. We are constantly retraining our ML models in order to test their accuracy. Below is the lifecycle of a model, which demonstrates its constant evolution.
- Model retraining: Every few months, we re-train the whole model. We input data and the output is the model.
- Model testing: We take the model and put in new data to test the model’s accuracy.
- Model deployment: When a model passes our validation and performance tests, we put this model into production.
- Inference of the model: On a daily basis, we input new data and output predictions.

AI Engine (high-level) Architecture
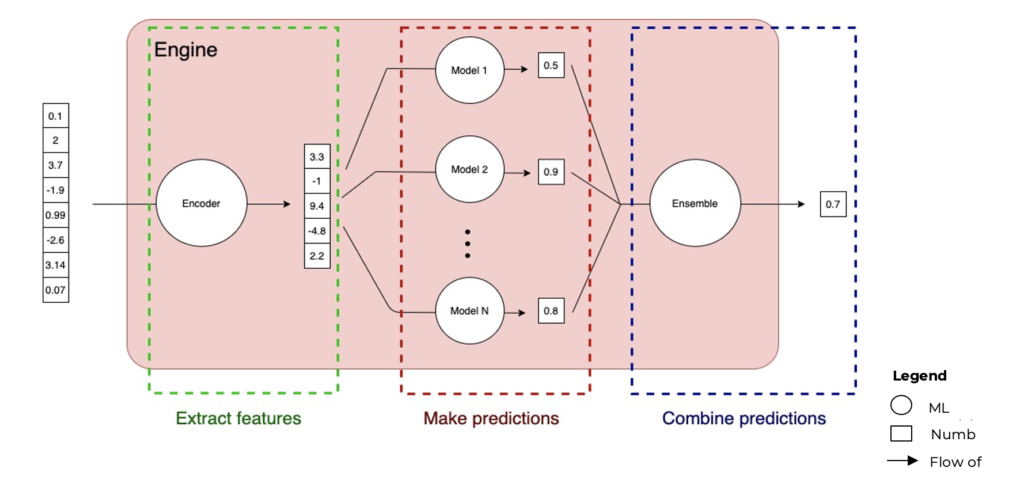
Now that we understand how a ML model works, let’s look at how we can use this information in the AI Engine. Let’s say we want to analyse the price of a stock. These are the 3 main steps in the Engine pipeline:
- Extract Features (Encode): We first take our input data, convert the data to a list of numbers, and give this list to the Engine. At the beginning of the Engine pipeline, it extracts important features. Basically, it takes the long list of numbers and compresses it to a shorter list (this happens through the unsupervised learning we talked about earlier – more specifically through our encoder models). We have a lot of data points, which could confuse our models, so we try to decrease their number in order for the models to have an easier time analysing and forecasting the output, as well as discarding redundant data.
- Make Predictions (Serving the Model): We take this list of numbers and feed it into the machine learning models. Each model has learned with a different machine learning algorithm. The aim of this process is to improve the predictive accuracy of the model. Each of the models has its own prediction of what the output will be.
- Combine Predictions (Ensemble): At the end, the last machine learning model combines all of our model predictions into a unique prediction, which is our signal. We provide this to the portfolio construction team to invest on and supply to asset managers.
Wrapping Up
Hopefully the concepts of AI and the AI Engine are a little less scary than at the beginning of this article. Here are some key takeaways:
- Artificial intelligence is a program with the ability to learn and reason similar to a human.
- The AI Engine is a group of ML models that take in financial and non-financial data and work together to attempt to analyse patterns and behaviours in equity markets.
- Supervised learning is when a program takes an input and learns to assign it an output.
- Unsupervised learning is when a computer program must find structure in the input data because it is unlabelled.
- The lifecycle of a ML model includes: model retraining, model testing, and the inference of the model.
- The AI Engine extracts features, makes predictions, and combines these predictions to create a signal.
This article by no means covers all the complexities of the AI Engine and only begins to explain how the ML models work. Each of our prediction models could have entire research papers written about them! However, for an AI novice this is the right place to start. Perhaps I’ll try my hand at learning some coding basics next…