
INSIGHTS Research
Von Sofia Kellogg, 6/09/2021
Wenn Sie mich vor vier Monaten gefragt hätten, was unüberwachtes Lernen ist und wie wir damit Modelle für maschinelles Lernen trainieren, hätte ich Sie mit einem leeren Blick bedacht. Mein Hintergrund ist Politikwissenschaft und Nachhaltigkeit mit einem allgemeinen Wissen über KI (engl. AI – Artificial Intelligence). Wenn ich allgemeines Wissen sage, meine ich damit das, was ich mir vorstelle, wenn ich an KI denke:

In meinen ersten Wochen habe ich mit den KI-Forschern und -Ingenieuren in unserem Team gesprochen, um besser zu verstehen, was KI genau ist und wie wir sie in der Arabesque-AI Engine einsetzen. Dank ihrer Anleitung verstehe ich jetzt, wie unsere AI Engine funktioniert (auf einem sehr hohen Niveau – ich bin noch lange keine Expertin). Wenn Sie Hilfe brauchen, um die AI Engine zu entschlüsseln, lesen Sie weiter. Ich hoffe, das wird Ihnen auf Ihrer Reise helfen.
Was ist KI?
Zunächst einmal: Was ist KI? Künstliche Intelligenz ist ein Programm mit der Fähigkeit zu lernen und zu denken wie ein Mensch. Maschinelles Lernen (ML) ist ein Teilbereich der KI. Von maschinellem Lernen spricht man, wenn ein Algorithmus in der Lage ist, bei einer bestimmten Art von Dateneingabe selbständig zu lernen. Ein Algorithmus ist eine Reihe von Instruktionen, die ein Computerprogramm ausführt. Algorithmen nehmen Eingaben entgegen und spucken Ergebnisse aus.
Was ist die Arabesque AI Engine?
Bei der Arabesque AI Engine handelt es sich um eine Gruppe von ML-Modellen, die Finanz- und Nicht-Finanzdaten aufnehmen und gemeinsam versuchen, Muster und Verhaltensweisen auf den Aktienmärkten zu analysieren. Bei diesem Prozess kann die AI Engine wesentlich mehr Daten analysieren als ein Mensch. Sie ist darauf ausgelegt, eine unvoreingenommene Analyse einer riesigen Datenmenge zu liefern und aus diesen Daten potenziell einzigartige Schlussfolgerungen zu ziehen. Außerdem wird die Komplexität der Daten erheblich reduziert, was zu einem besser skalierbaren Prozess führt. Wir verwenden eine Kombination aus überwachtem und unüberwachtem Lernen unter Einbeziehung von Finanzdaten und anderen Inputs, um die Wahrscheinlichkeit zu analysieren, mit welcher der Kurs einer Aktie in Zukunft steigt oder fällt.
AI Engine-Eingaben
Die AI Engine nimmt Daten auf und gibt die Signale (die Kursprognosen) aus, die wir bei der Portfoliokonstruktion verwenden. Wir geben eine Vielzahl von finanziellen und nicht-finanziellen Daten in die Engine ein. Wir betrachten zum Beispiel Kursrenditen, Nettogewinne, Gewinne pro Aktie und Indizes wie den S&P 500. Für unsere Eingabedaten benötigen wir mindestens 10 Jahre der gesamten Datenhistorie, um Vorhersagen treffen zu können. Darüber hinaus geben wir nicht-finanzielle Daten ein, wie Nachrichten und Medien (über Methoden der natürlichen Sprachverarbeitung („NLP“)) und ESG-Daten von unserem Schwesterunternehmen Arabesque S-Ray®. Alle diese Daten werden von den Algorithmen gleichbehandelt und die Modelle lernen auszuwählen, welche für das Universum des jeweiligen Vermögenswerts am relevantesten sind. Für jeden Vermögenswert, den wir analysieren möchten, sagt die Engine die Wahrscheinlichkeit voraus, ob der Preis eines Vermögenswerts im Vergleich zum entsprechenden Referenzindex steigt oder fällt.

Überwachtes Lernen
Beim überwachten Lernen nimmt ein Programm eine Eingabe auf und lernt, ihr eine Ausgabe zuzuordnen, die a priori bekannt ist. Rückkopplungsschleifen helfen bei der Anpassung der Ausgabe eines Modells. Zu diesem Zweck geben wir einem ML-Algorithmus eine Reihe von gekennzeichneten Daten, die als Trainingsbeispiel verwendet werden. Eine Einschränkung: Daten können immer noch verzerrt sein. Wenn ich ein Modell trainiere, um Katzen und Hunde zu klassifizieren, aber 99 % der Bilder, die ich dem Modell gebe, sind Hunde, dann wird das Modell eine Tendenz zu Hunden haben. Wir müssen sicherstellen, dass wir das Modell mit relevanten Informationen füttern. Im Folgenden sehen Sie ein Beispiel für die Klassifizierung mit überwachtem Lernen. Wir füttern den Algorithmus mit markierten Bildern von Hunden und Katzen, die er dann verwendet, um die Tiere zu kategorisieren und ihnen entsprechende Bezeichnungen zu geben.
Der Algorithmus ermittelt ein ML-Modell aus diesen Daten. Um es zu testen, geben wir ihm eine Eingabe, die es noch nie zuvor gesehen hat (z. B. ein unbeschriftetes Bild eines Hundes), um zu sehen, ob es die neuen Daten richtig sortiert und eine korrekte Ausgabe liefert.


Wenn das Modell die neuen Daten nicht richtig sortiert, versuchen wir weiter, den Algorithmus zu verbessern, in der Regel durch mehr Training oder ein Training mit einem vielfältigeren Datensatz (z. B. Labradore, Spaniels und Pudel). Das Problem beim überwachten Lernen ist, dass es zu menschlichen Fehlern oder seltenen Vorkommnissen kommen kann (z. B. geben wir ein Bild von einem Labrador ein, das aber als Spaniel getaggt wird). Es kann auch sehr lange dauern, bis alle benötigten Daten beschriftet sind (obwohl wir in diesem Fall eine Menge süßer Hundefotos sehen würden, was einige unserer Teammitglieder überhaupt nicht stören würde).
Unüberwachtes Lernen
Unüberwachtes Lernen bedeutet, dass ein Computerprogramm eine Struktur in den Eingabedaten finden muss, weil sie nicht gekennzeichnet sind. Es gibt verschiedene Arten des unüberwachten Lernens, z. B. Clustering, Reinforcement Learning, Dimensionalitätsreduktion usw. Das nachstehende Beispiel zeigt das Clustering, bei dem wir dem ML-Algorithmus eine Reihe von Eingaben geben, der Algorithmus Ähnlichkeiten zwischen diesen Eingaben findet und das ML-Modell lernt, diese Eingaben zusammenzufassen. In der AI Engine haben wir Hunderte von Eingabemerkmalen und wir müssen versuchen, diese Datenpunkte zu verdichten. Wir verwenden unüberwachtes Lernen, um die Eingabedaten zu komprimieren.

Lebenszyklus eines ML-Modells
Es ist wichtig zu beachten, dass das Training eines ML-Modells kein einmaliger Prozess ist. Wir trainieren unsere ML-Modelle ständig neu, um ihre Genauigkeit zu testen. Im Folgenden ist der Lebenszyklus eines Modells dargestellt, der seine ständige Weiterentwicklung verdeutlicht.
Umschulung des Modells: Alle paar Monate trainieren wir das gesamte Modell neu. Wir geben Daten ein und das Ergebnis ist das Modell.
Modellprüfung: Wir nehmen das Modell und geben neue Daten ein, um die Genauigkeit des Modells zu testen.
Implementierung des Modells: Wenn ein Modell unsere Validierungs- und Leistungstests bestanden hat, bringen wir es in die Produktion ein.
Inferenzen des Modells: Täglich geben wir neue Daten ein und erstellen Vorhersagen.

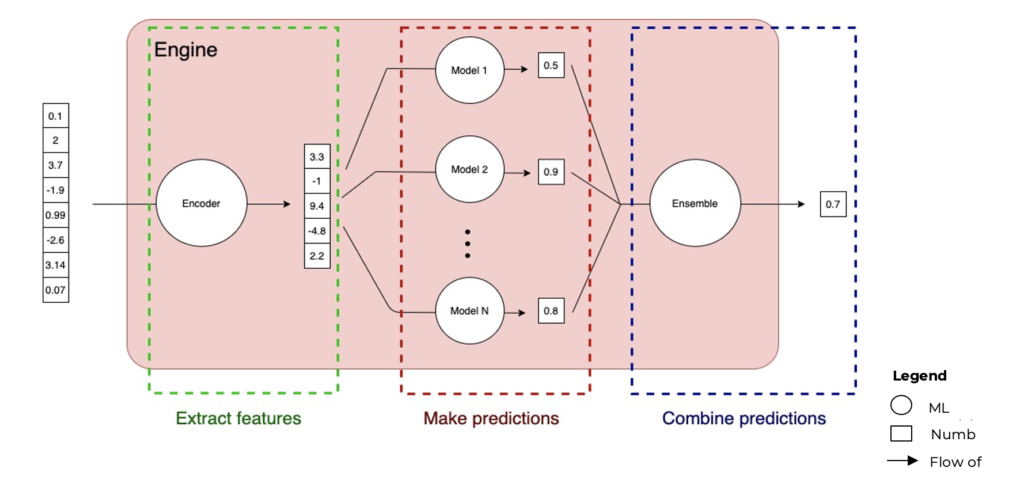
AI Engine (high-level) Architektur
Da wir nun wissen, wie ein ML-Modell funktioniert, wollen wir uns ansehen, wie wir diese Informationen in der AI Engine nutzen können. Nehmen wir an, wir wollen den Kurs einer Aktie analysieren. Dies sind die 3 Hauptschritte in der Engine-Pipeline:
Merkmale extrahieren (kodieren): Wir nehmen zunächst unsere Eingabedaten, wandeln sie in eine Liste von Zahlen um und geben diese Liste an die Engine weiter. Am Anfang der Engine-Pipeline extrahiert sie wichtige Merkmale. Im Grunde genommen wird die lange Zahlenliste zu einer kürzeren Liste komprimiert (dies geschieht durch das unüberwachte Lernen, über das wir bereits gesprochen haben – genauer gesagt durch unsere Encoder-Modelle). Da wir viele Datenpunkte haben, die unsere Modelle verwirren könnten, versuchen wir, ihre Anzahl zu verringern, damit die Modelle die Analyse und die Vorhersage der Ergebnisse erleichtern und überflüssige Daten aussortieren können.
Vorhersagen treffen (dem Modell dienen): Wir nehmen diese Liste von Zahlen und geben sie in die Modelle für maschinelles Lernen ein. Jedes Modell hat mit einem anderen Algorithmus für maschinelles Lernen gelernt. Ziel des Prozesses ist es, die Vorhersagegenauigkeit des Modells zu verbessern. Jedes der Modelle hat seine eigene Vorhersage, wie die Ausgabe aussehen wird.
Kombinieren von Vorhersagen (Gesamtheit): Am Ende kombiniert das letzte maschinelle Lernmodell alle unsere Modellvorhersagen zu einer einzigen Vorhersage, die unser Signal ist. Dieses Signal stellen wir dem Team für die Portfoliokonstruktion zur Verfügung, das daraufhin investiert und es den Vermögensverwaltern zur Verfügung stellt.
Abschließende Zusammenfassung
Ich hoffe, dass die Konzepte der KI und der AI Engine etwas weniger beängstigend sind als zu Beginn dieses Artikels. Hier sind einige wichtige Erkenntnisse:
- Künstliche Intelligenz ist ein Programm mit der Fähigkeit, ähnlich wie ein Mensch zu lernen und zu denken.
- Die AI Engine ist eine Gruppe von ML-Modellen, die Finanz- und Nicht-Finanzdaten aufnehmen und zusammen versuchen, Muster und Verhaltensweisen auf den Aktienmärkten zu analysieren.
- Beim überwachten Lernen nimmt ein Programm eine Eingabe auf und lernt, ihr eine Ausgabe zuzuordnen.
- Unüberwachtes Lernen bedeutet, dass ein Computerprogramm eine Struktur in den Eingabedaten finden muss, weil diese nicht gekennzeichnet sind.
- Der Lebenszyklus eines ML-Modells umfasst Umlernen des Modells, Testen des Modells und Inferenzen des Modells.
- Die AI-Engine extrahiert Merkmale, trifft Vorhersagen und kombiniert diese Vorhersagen, um ein Signal zu erzeugen.
Dieser Artikel deckt bei weitem nicht alle Komplexitäten der AI Engine ab und erklärt nur ansatzweise, wie die ML-Modelle funktionieren. Über jedes unserer Prognosemodelle könnte man ganze Forschungsarbeiten schreiben! Für einen KI-Neuling ist dies jedoch der richtige Ort, um anzufangen. Vielleicht versuche ich als Nächstes, ein paar Grundlagen des Programmierens zu lernen…