
Arabesque AI blog
INSIGHTS Stellungnahmen
Hallo! Ich bin Mabelle, KI-Forscherin bei Arabesque AI und arbeite in der Forschung und Entwicklung. Ich bin auf Natural Language Processing (NLP) spezialisiert und verbringe den größten Teil meiner Forschungszeit mit der Analyse von Social-Media-Daten. Während meiner Doktorarbeit extrahierte ich diskrete Emotionen aus historischen Tweets und nutzte sie, um Twitter-Benutzer mit Depressionsrisiko zu identifizieren. Bei Arabesque AI konzentriere ich mich nun darauf, wie wir zukünftige Aktienkursbewegungen mit Hilfe von Twitter-Daten abschätzen können. In diesem Beitrag werde ich Ihnen erläutern, wie dies unter Verwendung von Twitter-Daten für ein anonymisiertes Unternehmen erreicht werden könnte.
von Dr. Mabelle Chen
Mit dem revolutionären Wachstum der sozialen Medien ist die Verwendung großer Datenmengen zum neuesten Trend für Forscher geworden, die Aktienmarktbewegungen analysieren. Unter Verwendung von Techniken aus dem NLP ist die Stimmungsanalyse die vorherrschende Methode zur Extraktion von Merkmalen aus solchen Datenquellen gewesen. Eine kurze Suche von „stock market prediction Twitter“ auf Google Scholar wird zeigen, dass 9 von 10 Arbeiten entweder „sentiment analysis“ oder „mood“ im Titel haben, was eine Allgegenwart der Stimmungsanalyse in NLP-Anwendungen demonstriert. Siehe zum Bollen et al. (2011), Mittal et al. (2011), Yu et al. (2012), Nguyen und Shirai (2015), und Sahana et al. (2019). The concept of using sentiment analysis to predict stock price movements has its origins in behavioural economics. According to Nofsinger (2010), Das Konzept der Verwendung der Stimmungsanalyse zur Vorhersage von Aktienkursbewegungen hat seinen Ursprung in der Verhaltensökonomie. Nach Nofsinger (2010) beeinflusst der Grad des Optimismus oder Pessimismus in einer Gesellschaft die Entscheidungen von Konsumenten, Investoren und Führungskräften von Unternehmen. Dies hat einen Einfluss auf die Gesamtinvestitionen und die Geschäftstätigkeit, was darauf hindeutet, dass die gesellschaftliche Stimmung dazu beitragen kann, zukünftige finanzielle und wirtschaftliche Aktivitäten abzuschätzen. Daher versuchen viele Forscher, die Bewegung des Marktes anhand der Dynamik von Unternehmen, wirtschaftlicher Szenarien und öffentlicher Stimmungen vorherzusagen.
Ist jedoch das Stimmungsbild das einzig sinnvolle Merkmal, das man aus solchen Daten extrahieren kann? Die Antwort ist definitiv nein. In diesem Beitrag untersuche ich, welche anderen Informationen und Merkmale aus Tweets extrahiert werden können und wie effektiv diese zusätzlichen Merkmale in Verbindung mit der Stimmung für die Schätzung künftiger Aktienkursbewegungen sind.
Dieser Blog ist in vier Abschnitte unterteilt:
-
Merkmale: Zu Beginn stelle ich eine Reihe von Features vor, die aus Twitter-Daten extrahiert werden können und sich diesen drei Kategorien zuordnen lassen:
-
Vorhersage:: Ich experimentiere dann mit diesen Merkmalen, um zu beurteilen, wie sie zur Vorhersage der Bewegung von vier Aktienzielen verwendet werden können.
-
Erläuterung: Als Nächstes verwende ich die Modellinterpretation, um zu untersuchen, wie diese Merkmale zu den einzelnen Vorhersageaufgaben beitragen.
-
Schlussfolgerung: Abschließend teile ich meine Schlussfolgerung zur Leistung plattformspezifischer und inhaltsbasierter Merkmale im Vergleich zur Stimmung.
Merkmale: Was können wir also wirklich an Tweets messen?
Während das Extrahieren der Stimmung aus Tweets ziemlich einfach ist, steckt tatsächlich eine Fülle von Informationen in jedem. In diesem Abschnitt gehe ich auf all die verschiedenen Arten von Merkmalen ein, die aus diesen Tweets extrahiert werden können. Einige von ihnen könnten sich für Modellierungszwecke als nützlich erweisen. Zur Demonstration habe ich ein bestimmtes Unternehmen als Beispiel untersucht, das als Firma A bezeichnet wird. Ich habe
tweepy (einen Python-Wrapper für die Twitter-API) verwendet, um öffentliche Tweets zu sammeln, in denen diese Firma vom 26. November 2019 bis zum 20. Juli 2020 erwähnt wurde. Insgesamt wurden 85.490 Tweets gesammelt, die sich über 242 Tage erstreckten. Die Verteilung dieser Tweets ist in der folgenden Tabelle dargestellt. Die Tweets wurden täglich gruppiert, um eine Reihe von aggregierten Merkmalen für jeden Tag zu erstellen.
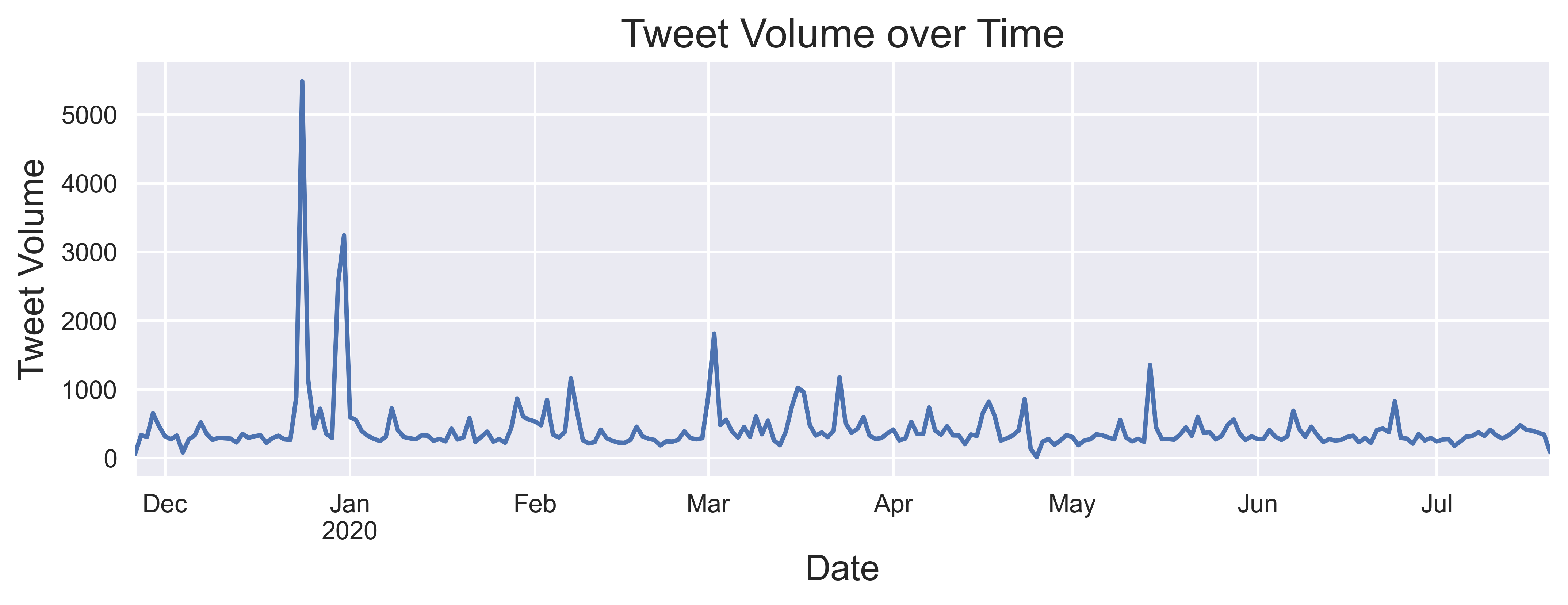
Bevor diese Merkmale beschrieben werden, ist es wichtig zu betonen, dass es sich bei allen Merkmalen um Momentaufnahmen handelt, die am Ende eines jeden Tages gemacht werden. Bei jedem Tweet könnte die Anzahl der Likes und Retweets von Tag zu Tag weiter zunehmen. Wenn keine Momentaufnahmen gemacht werden, enthalten die Daten Informationen aus der Zukunft enthalten. Diese häufige Gefahr beim maschinellen Lernen wird als Datenverlust bezeichnet. Da unsere Daten als Zeitreihen vorliegen, ist es absolut entscheidend, dass wir diesen Fehler für zukünftige Prognosen nicht machen. Lassen Sie uns nun die Merkmale untersuchen, die für Modellierungszwecke generiert werden können, wie im folgenden Diagramm dargestellt.

-
Zu Beginn können einige einfache Statistiken relativ leicht extrahiert werden, wie z. B. das Volumen der Tweets und die durchschnittliche Länge der Tweets pro Tag. Man kann jederzeit kreativ werden und weitere Maße in dieser Kategorie definieren. Die Verteilungen der einzelnen Features für den gesamten Datensatz sind in den nachfolgenden Diagrammen unten dargestellt.
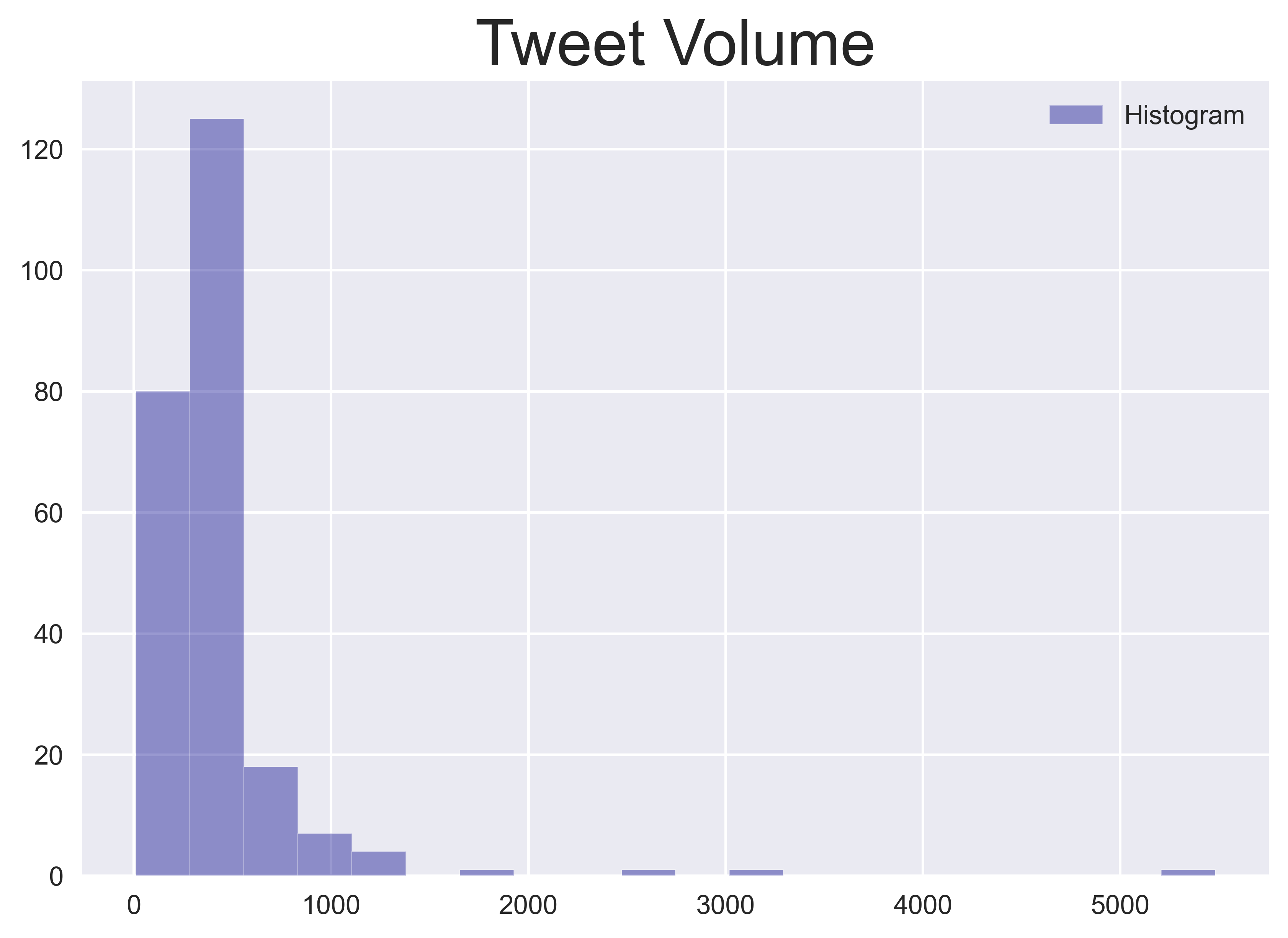
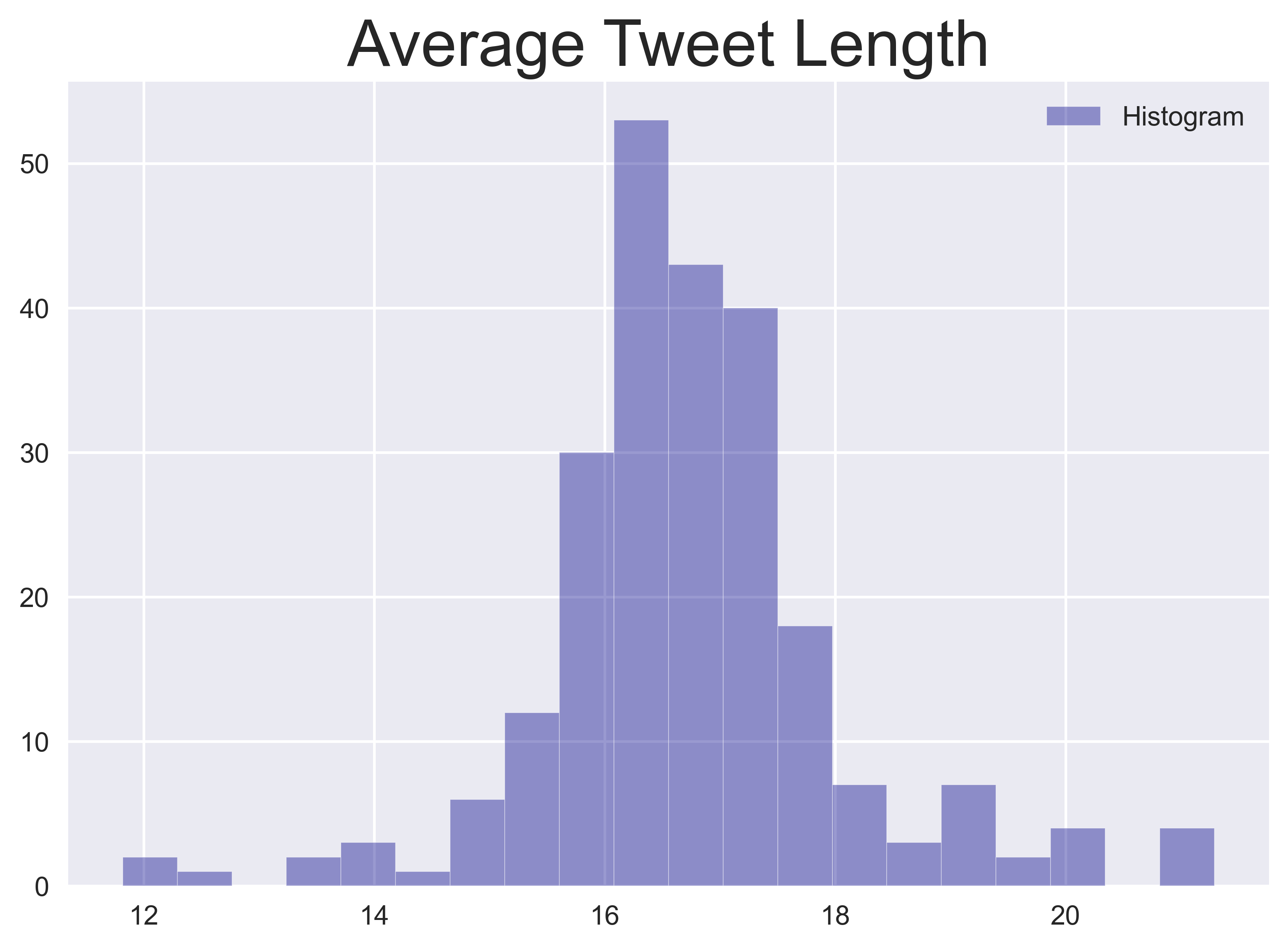
-
Funktionen der Twitter-Plattform
Twitter bietet eine Reihe von Funktionen, mit denen Online-Nutzer sich mitteilen und Inhalte austauschen können. Diese plattformspezifischen Funktionen können als Features genutzt werden. Beispielsweise können aus der Verwendung von Hashtags zwei Kennzahlen erstellt werden, indem 1) die Anzahl der verwendeten eindeutigen Hashtags und 2) die Gesamtzahl der verwendeten Hashtags gezählt wird. Da Hashtags zum Markieren des Themas oder der Thematik eines Tweets verwendet werden, beschreiben diese Funktionen, wie viele spezifische Themen an einem Tag diskutiert werden und wie groß der Umfang dieser Themen ist.


Das gleiche Verfahren kann für die Erwähnungen von Benutzern angewendet werden, um die Anzahl der einmaligen Erwähnungen und die Gesamtzahl der Erwähnungen zu erhalten, die den Umfang der Benutzerinteraktionen durch Tweets an einem bestimmten Tag beschreiben.

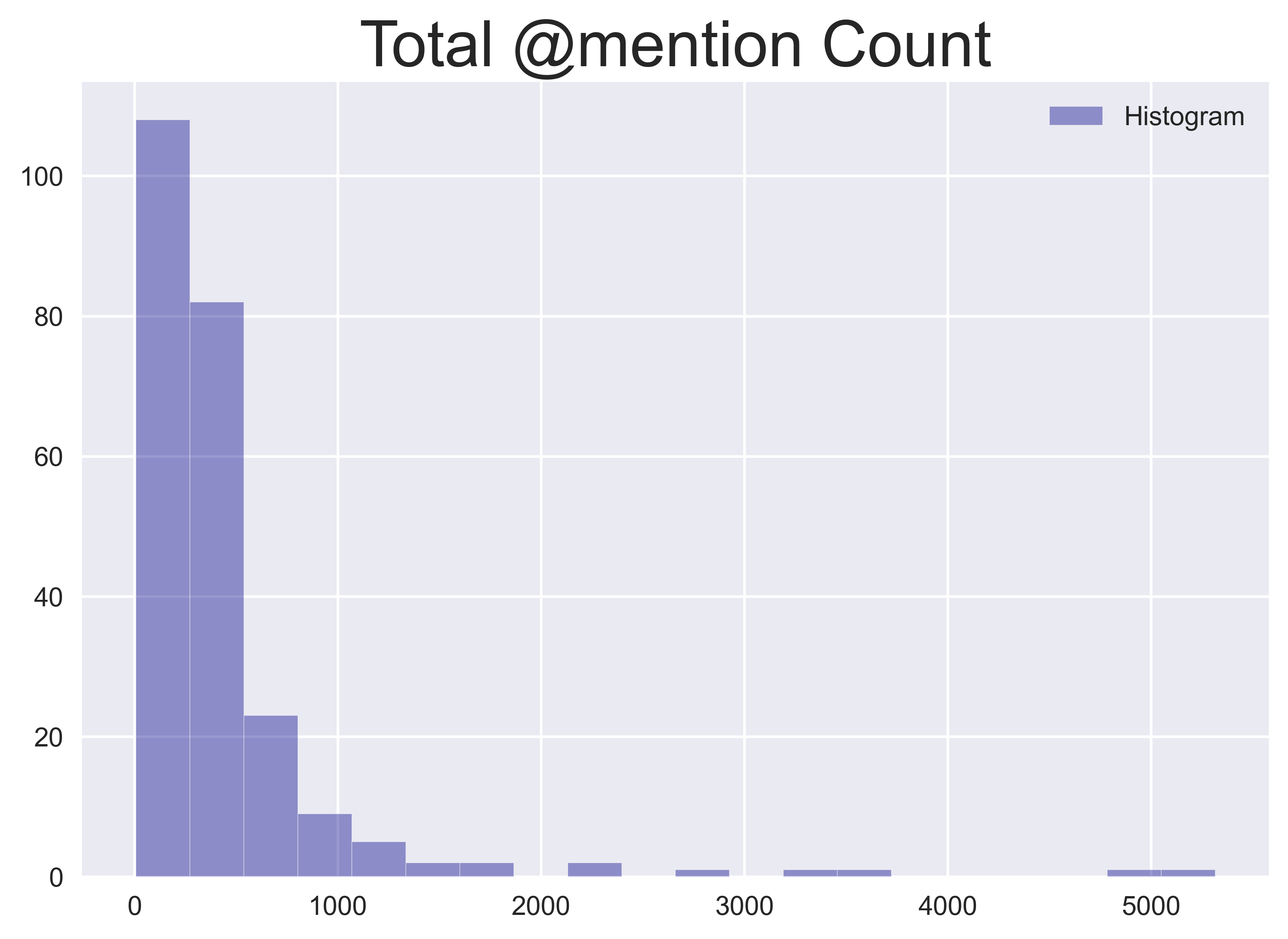
Eine weitere wichtige Funktion von Twitter ist das Retweet. Durch Extrahieren des Retweet-Volumens und seines Verhältnisses zu allen Tweets an einem bestimmten Tag kann ich erfassen, ob ein Trend-Tweet oder ein Thema viral geworden ist, was die Wahrscheinlichkeit erhöht, dass es soziale Auswirkungen hat. Um diese Informationen zusammenzufassen, berechne ich die durchschnittliche Anzahl der Retweets und das Verhältnis der Retweets zu allen Tweets für jeden Tag.


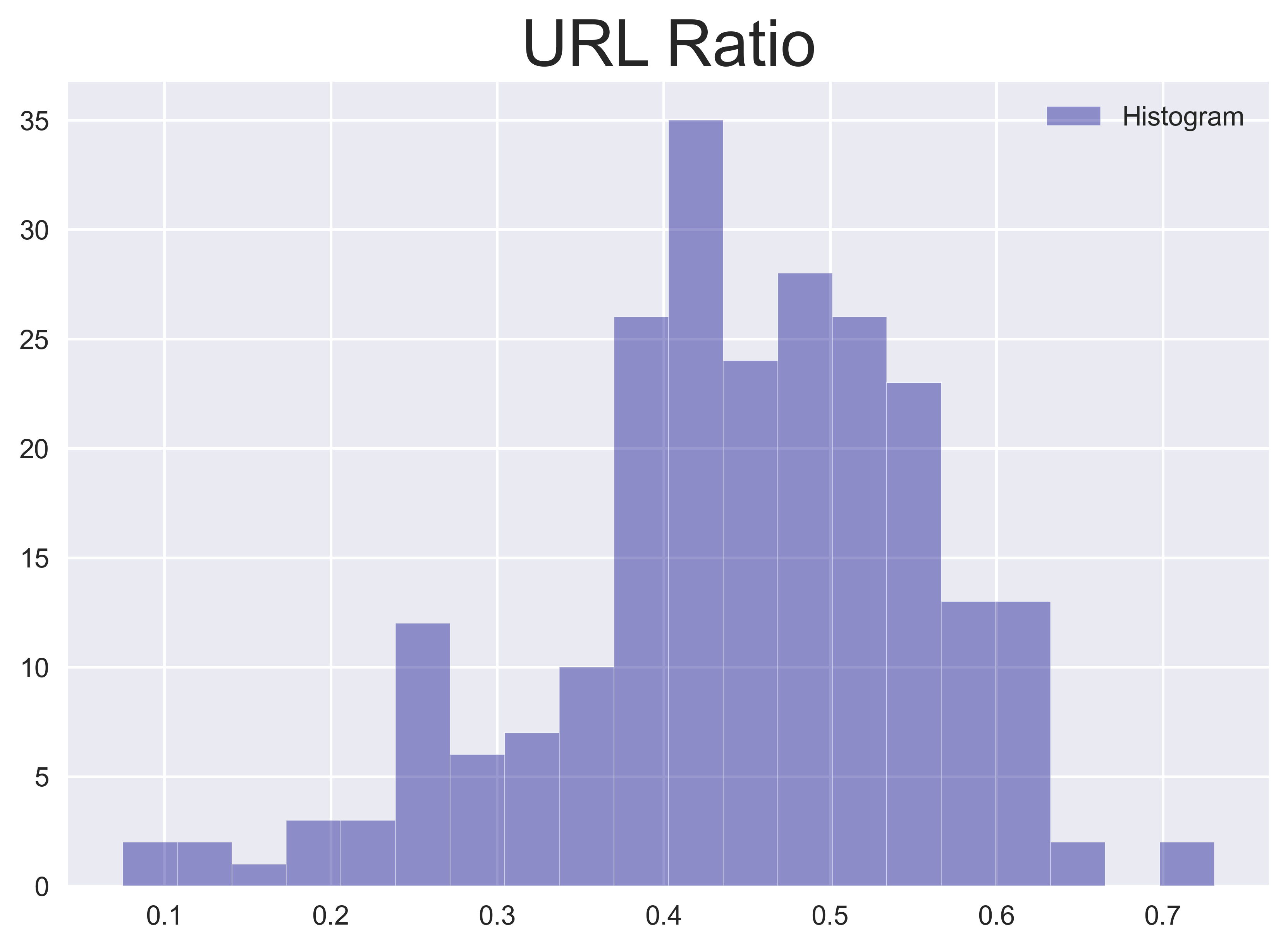
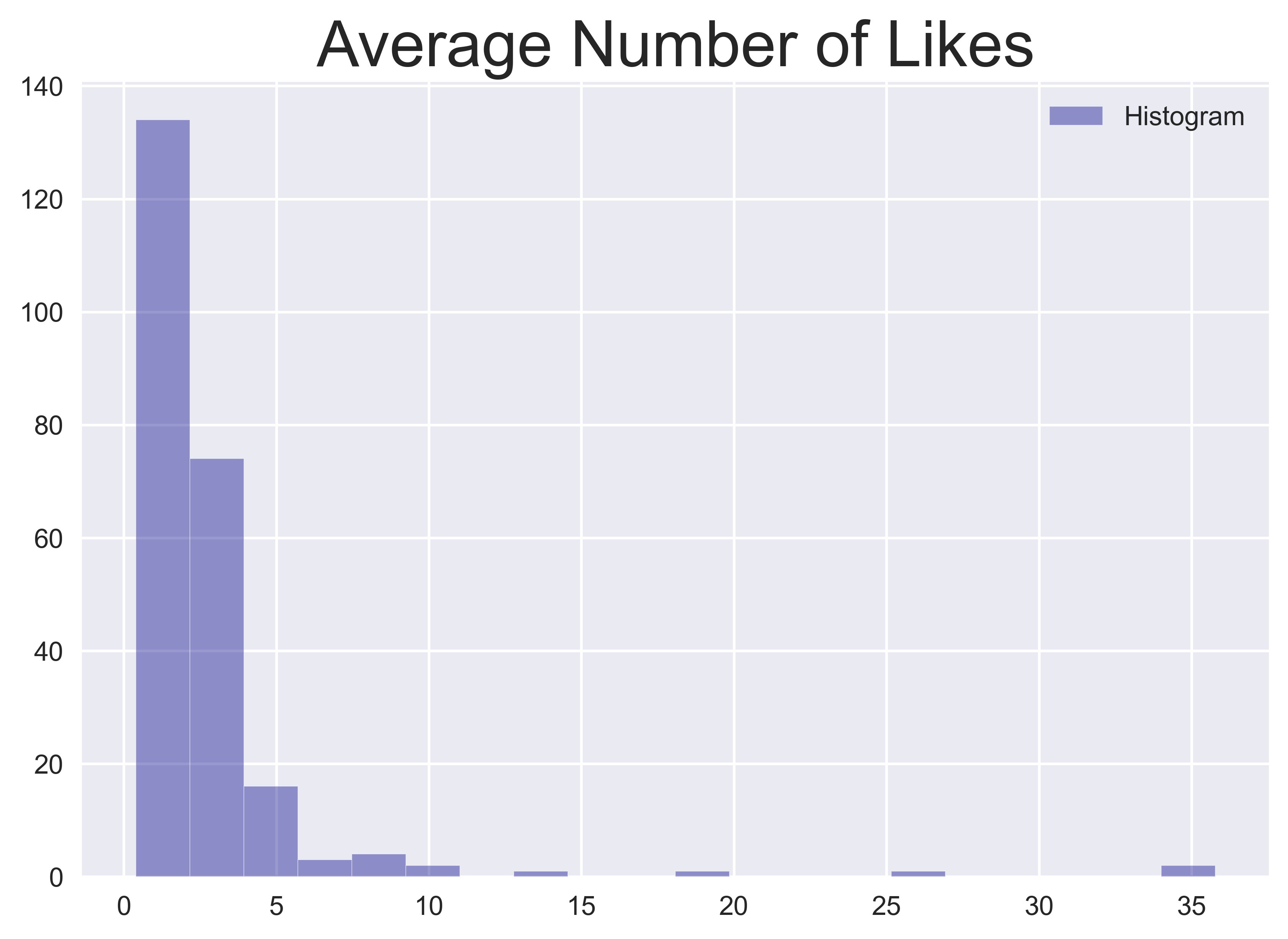
In ähnlicher Weise enthalten Freigaben eines externen Links (in Form einer URL) oder ähnliche Tweets Informationen darüber, welche Inhalte an einem bestimmten Tag die meiste öffentliche Aufmerksamkeit erregt haben. Um diese Informationen zu erfassen, berechne ich den prozentualen Anteil der Tweets, die URLs enthalten, an allen Tweets an einem bestimmten Tag als URL-Verhältnis und die durchschnittliche Anzahl von Likes pro Tweet für jeden Tag.
-
Tauchen wir nun in den eigentlichen Inhalt von Tweets ein und wenden NLP-Techniken auf den Text an. Wenn wir einen Text lesen, konzentrieren wir uns gewöhnlich auf die Einheiten oder Themen, die diskutiert werden, welche Themen behandelt werden und die Meinung oder das Gefühl, das der Autor zu vermitteln versucht. Dies wird von unseren Gehirnen automatisch verarbeitet. NLP-Techniken ermöglichen es Maschinen, die gleiche Funktion nachzuahmen.
-
In Tweets erwähnte benannte Einheiten
Benannte Einheiten (NEs) sind eine Reihe von vordefinierten Kategorien, die in unstrukturiertem Text erwähnt werden, wie z. B. der Name einer Person, Organisationen, Orte, Zeitangaben, Mengen, Geldbeträge und Prozentsätze. Die Aufgabe, diese NEs zu identifizieren, vorherzusagen und zu extrahieren, wird als Named Entity Recognition (NER) bezeichnet. Um zu demonstrieren, wie dies funktioniert, stellen Sie sich vor, ich poste den folgenden Tweet: „Letzte Woche traf ich Tim an der Londoner Börse in London“. Wie auf dem nächsten Bild zu sehen ist, ist NER in der Lage, den Inhalt dieses Tweets in die in der nachstehenden Tabelle beschriebenen NEs einzuordnen.

Davon ausgehend kann ich beginnen, den eigentlichen Inhalt eines Tweets zu verstehen. Mit NER kann ich Merkmale erstellen, die beschreiben, welche Art von Themen diskutiert werden. Diese verschiedenen Einheiten-Typen können für ein bestimmtes Unternehmen unterschiedliche Auswirkungen haben.
TYP BESCHREIBUNG Datum Absolute oder relative Daten oder Zeiträume. Ereignis Genannte Hurrikane, Kämpfe, Kriege, Sportereignisse usw. GPE Geopolitische Einheit, d. h. Länder, Städte, Staaten. Ort Nicht-GPE-Orte, Bergketten, Gewässer. Geld Finanzielle Werte, einschließlich Einheit. NORP Nationalitäten oder religiöse oder politische Gruppen. Organisation Unternehmen, Agenturen, Institutionen usw. Prozentsatz Prozentsatz, einschließlich „%“. Produkt Gegenstände, Fahrzeuge, Lebensmittel usw. (Nicht Dienstleistungen.) Person Personen, einschließlich fiktiver Personen. Mit dem NER-Tagger von
spacy(einem Python-Paket für NLP), werden insgesamt 20 Objekttypen aus unseren täglichen Tweets erkannt. Ich habe in der nachstehenden Tabelle einige gebräuchliche ausgewählt, die zum Experimentieren sinnvoll erscheinen. Für jeden Objekttyp sammle ich die Zählungen aus Tweets am selben Tag und erstelle 10 NE-Merkmale für jeden Tag.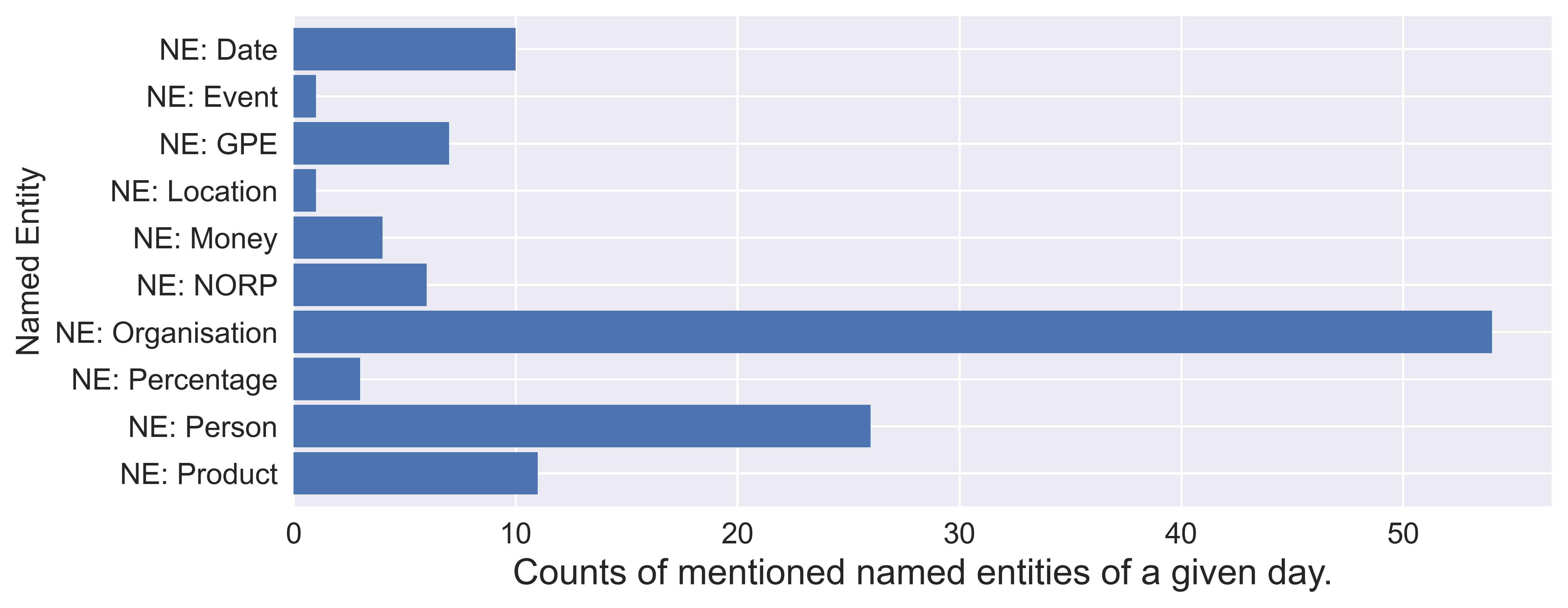
-
Themen / Cluster
Um zu erfassen, worüber die Öffentlichkeit an einem bestimmten Tag spricht, können Themenmodellierungen oder Clustering eingesetzt werden, die den Tweet-Strom in kleinere und spezifischere „Teilströme“ unterteilen. Aus diesen Unterströmen können kompliziertere Funktionen und Modelle erstellt werden. In dieser Kategorie ist allein die Erkennung von Finanzereignissen auf Twitter ein beliebtes und schnell wachsendes Forschungsgebiet. Hier verwende ich jedoch zur Demonstration eine einfachere Methode für die Extraktion von Merkmalen. Ohne allzu sehr ins Detail zu gehen, generiere ich für jeden Tweet sogenannte „Term Frequency Inverse Document Frequency“-Vektoren (tf-idf) und speise sie in
DBSCANein, um die Anzahl der Cluster zu ermitteln. Für alle Tweets (mit Duplikation, d. h. Retweets) weise ich jeden Tweet seinem Cluster zu und berechne das Verhältnis dieser Tweets zu allen Tweets. Diese Merkmale beschreiben, wie viele Mainstream-Themen von der Twitter-Öffentlichkeit an einem bestimmten Tag geäußert werden und wie hoch der Anteil des Engagements zu diesen Themen ist.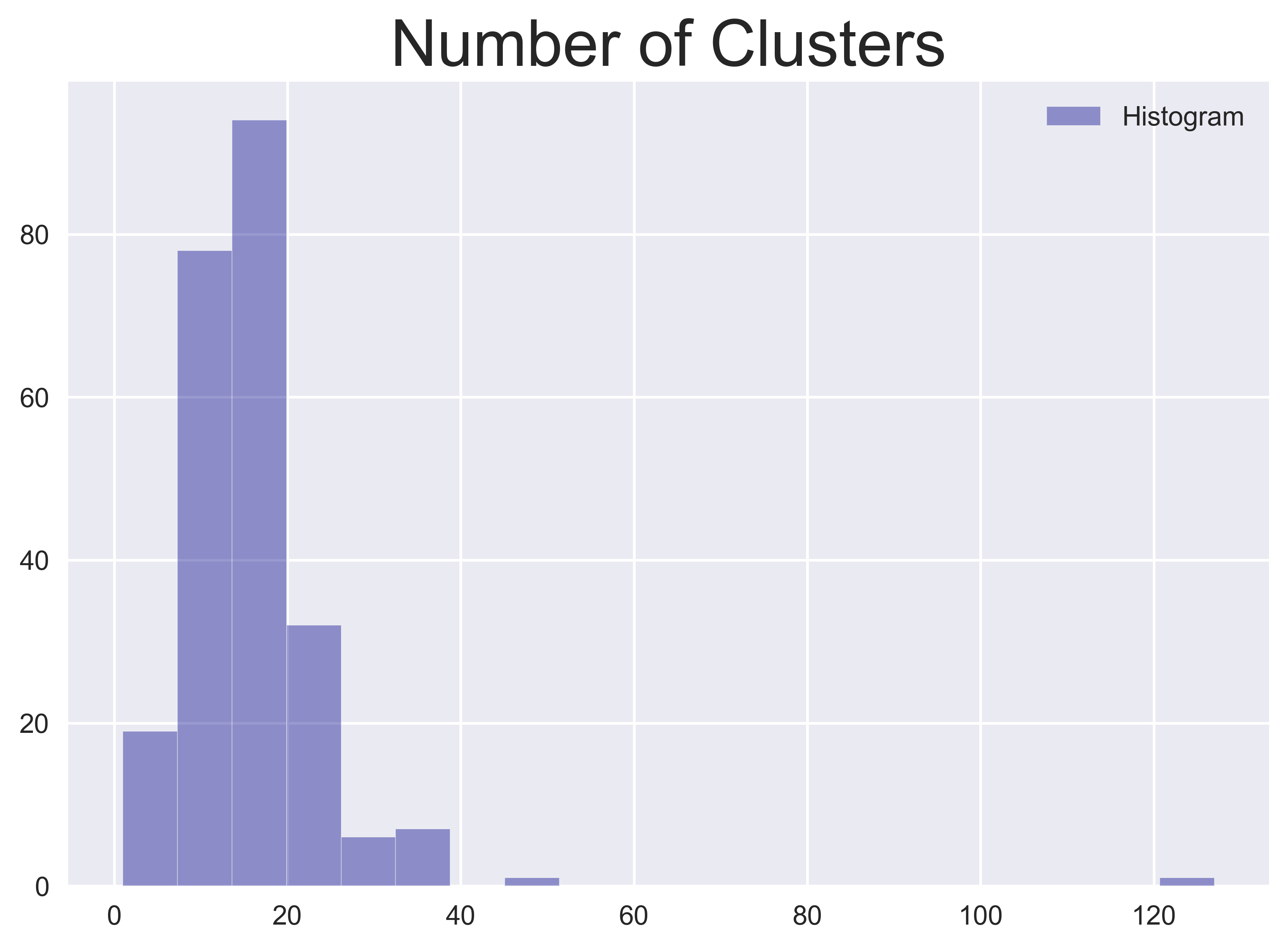
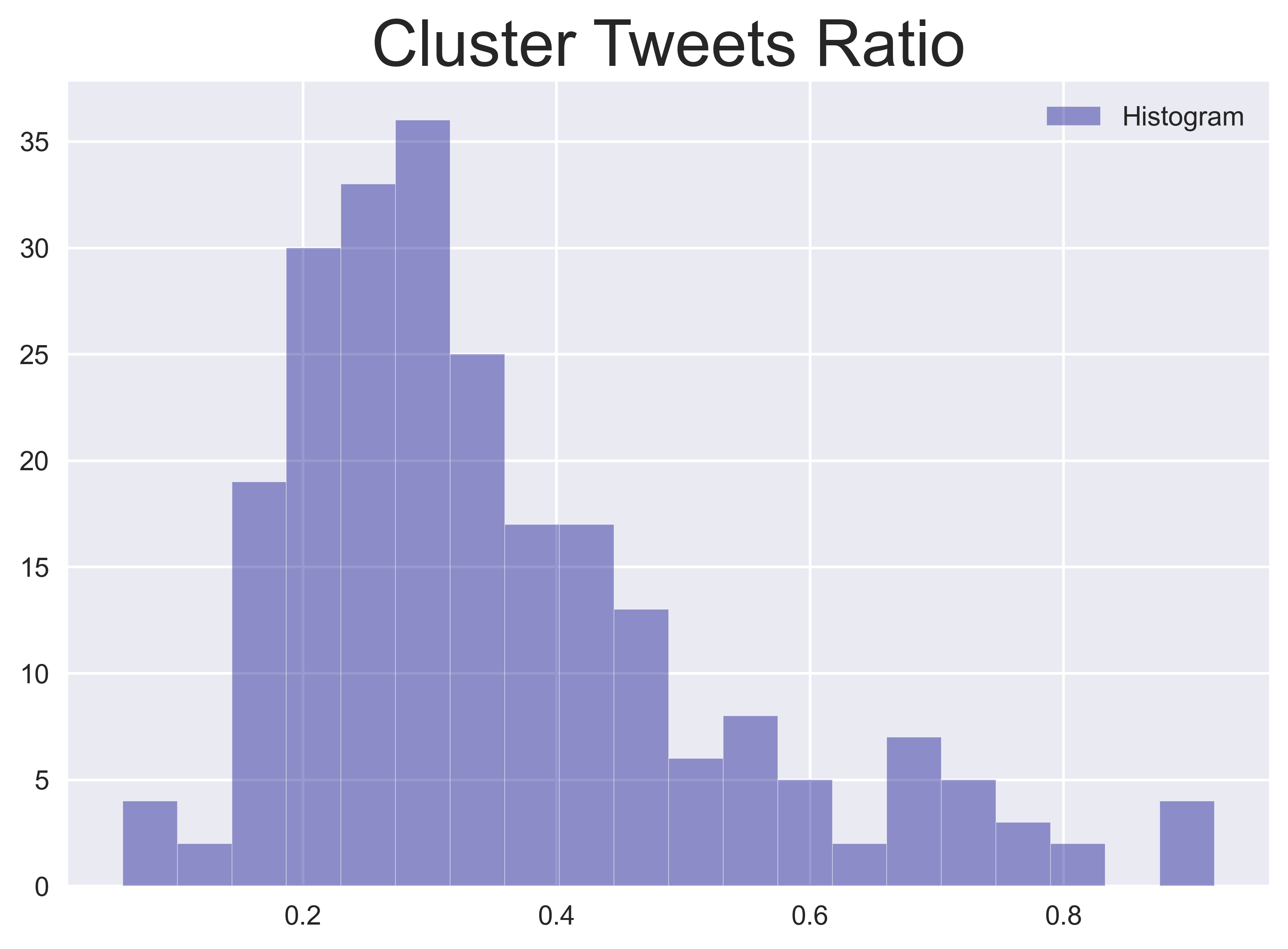
-
Stimmung
Es gibt eine Reihe von Programmen zur Erstellung der Stimmungsbewertung aus dem Text. Anstatt uns auf ein bestimmtes Programm festzulegen, sollten wir den Durchschnitt aus den Bewertungen zweier populärer Stimmungsanalyse-Programme,
afinnundvader, bilden. Jede dieser beiden Stimmungswerte wird auf den Bereich $[-1, 1]$ skaliert, wobei $0$ für eine neutrale Stimmung und $(0, 1]$ und $[-1, 0)$, für eine positive bzw. negative Stimmung stehen. Die Endwerte werden anhand der Länge des Tweets (Wortzahl) normalisiert und über die Tweets desselben Tages gemittelt.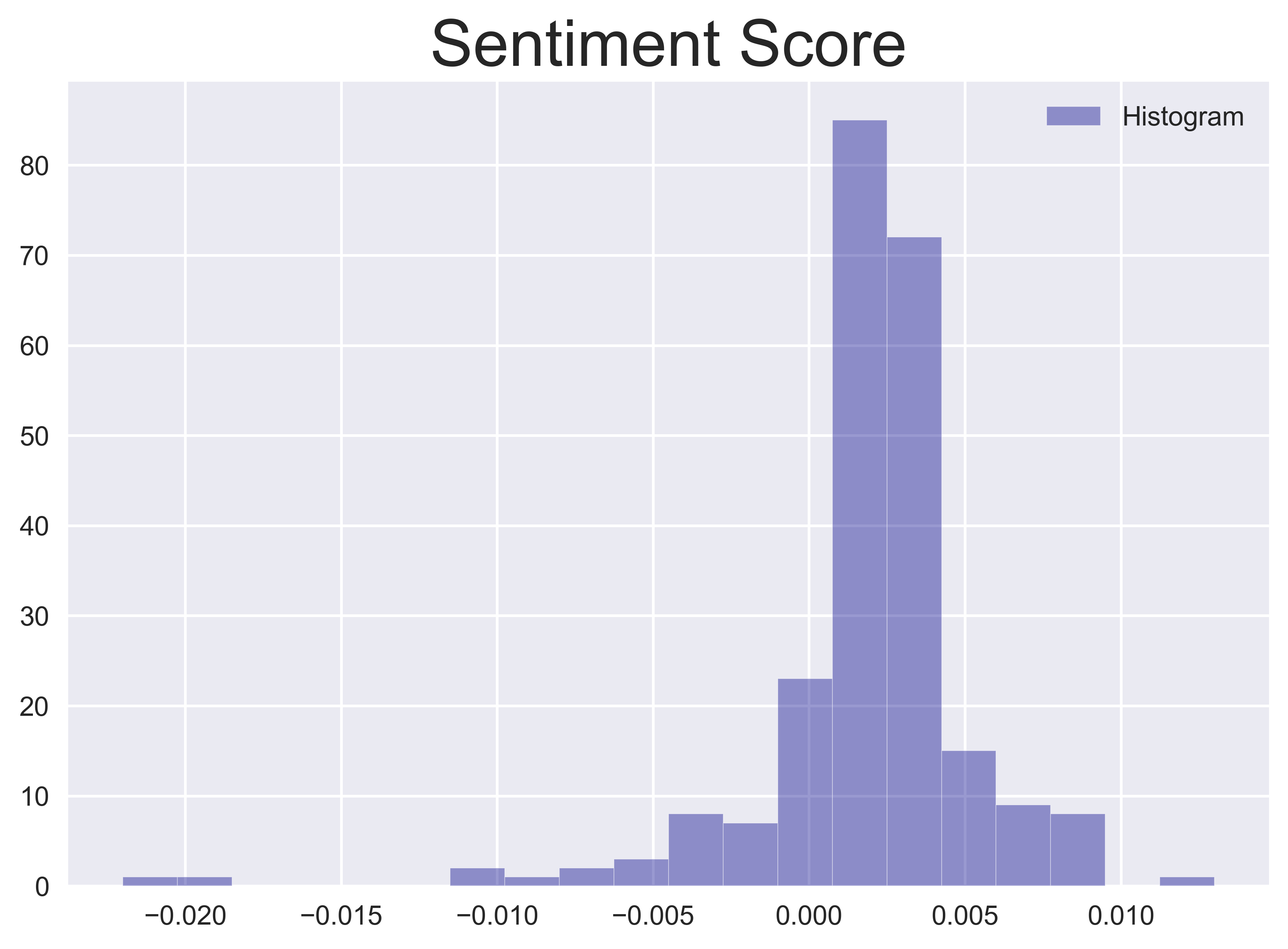
-
Vorhersage: Wie verhalten sich die Funktionen?
Bisher habe ich aus Tweets, die ich für Unternehmen A gesammelt habe, 23 tägliche Features generiert, d.h. eine Matrix von 238 (Tage/Aufzeichnungen) x 23 (Messungen/Features). Lassen Sie uns für diese Studie einige Klassifizierungsziele definieren, die ich mit diesen Merkmalen vorherzusagen versuchen kann. Ich definiere vier binäre Klassifizierungskennzeichen, die angeben, ob der 1) angepasste Schlusskurs, 2) die tägliche Rendite, 3) das Handelsvolumen und 4) die tägliche Volatilität einer Aktie im Laufe des nächsten Tages um einen bestimmten Schwellenwert ansteigen werden. Mathematisch kann dies als Zeichen $\Delta Z$ bezeichnet werden. Mit diesen vier Zielen experimentiere ich mit einem einfachen binären Klassifikationsmodell.
Für alle verfügbaren Daten des Datensatzes (26. November 2019 bis 20. Juli 2020) berechne ich den gleitenden Mittelwert der Merkmale von Datum $t$ bis $t-n$ um störende Fluktuationen zu glätten, wobei die Anzahl der Tage $n$ ein Hyperparameter ist. Dieser Merkmalssatz ($X$) wird mit jedem der vier Zielkennzeichen für den nächsten Tag $t+1$ ($y$) als Datensatz für Klassifikationsexperimente gepaart. Die ersten sieben Monate des Datensatzes (Nov 2019 – Mai 2020) werden für das Training verwendet, die restlichen zwei Monate (Jun und Jul 2020) dienen zum Testen und Bewerten der Wirksamkeit der Merkmale. Ich wähle für diese Aufgabe ein einfaches logistisches Regressionsmodell (aus dem maschinellen Lernpaket scikit-learn), damit sich die Leistung mehr auf die Merkmale als auf das Lernmodell stützt.
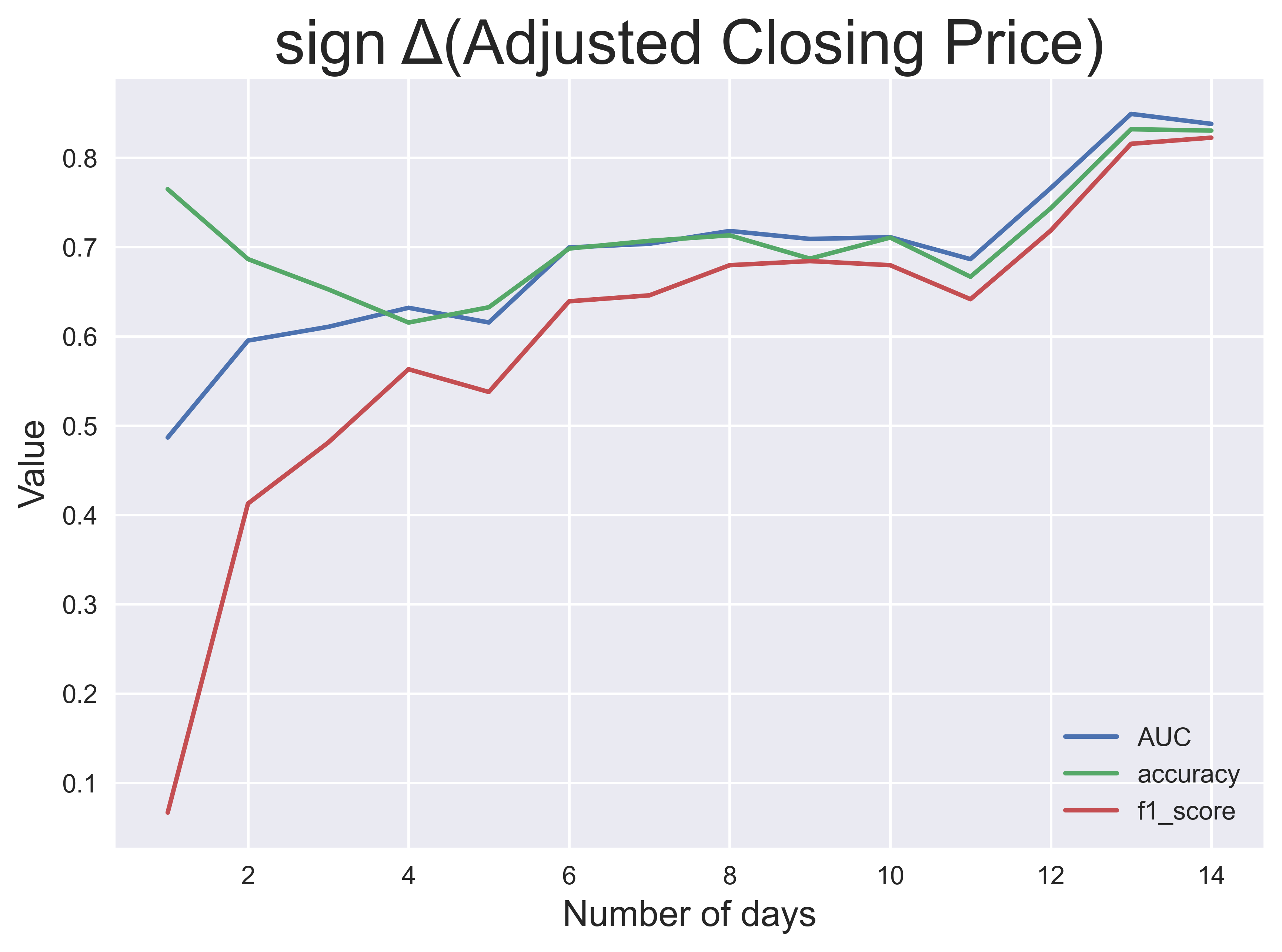
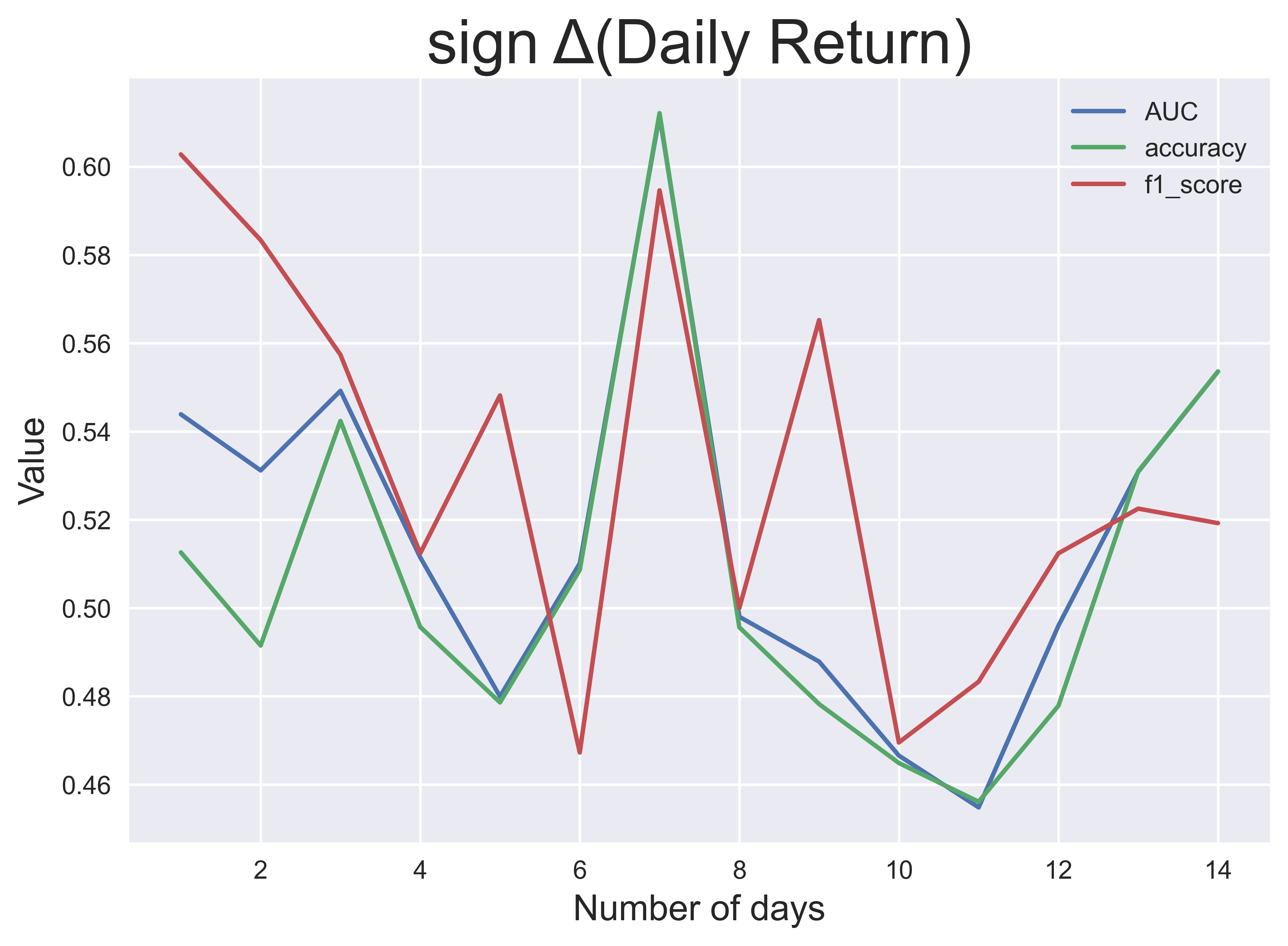
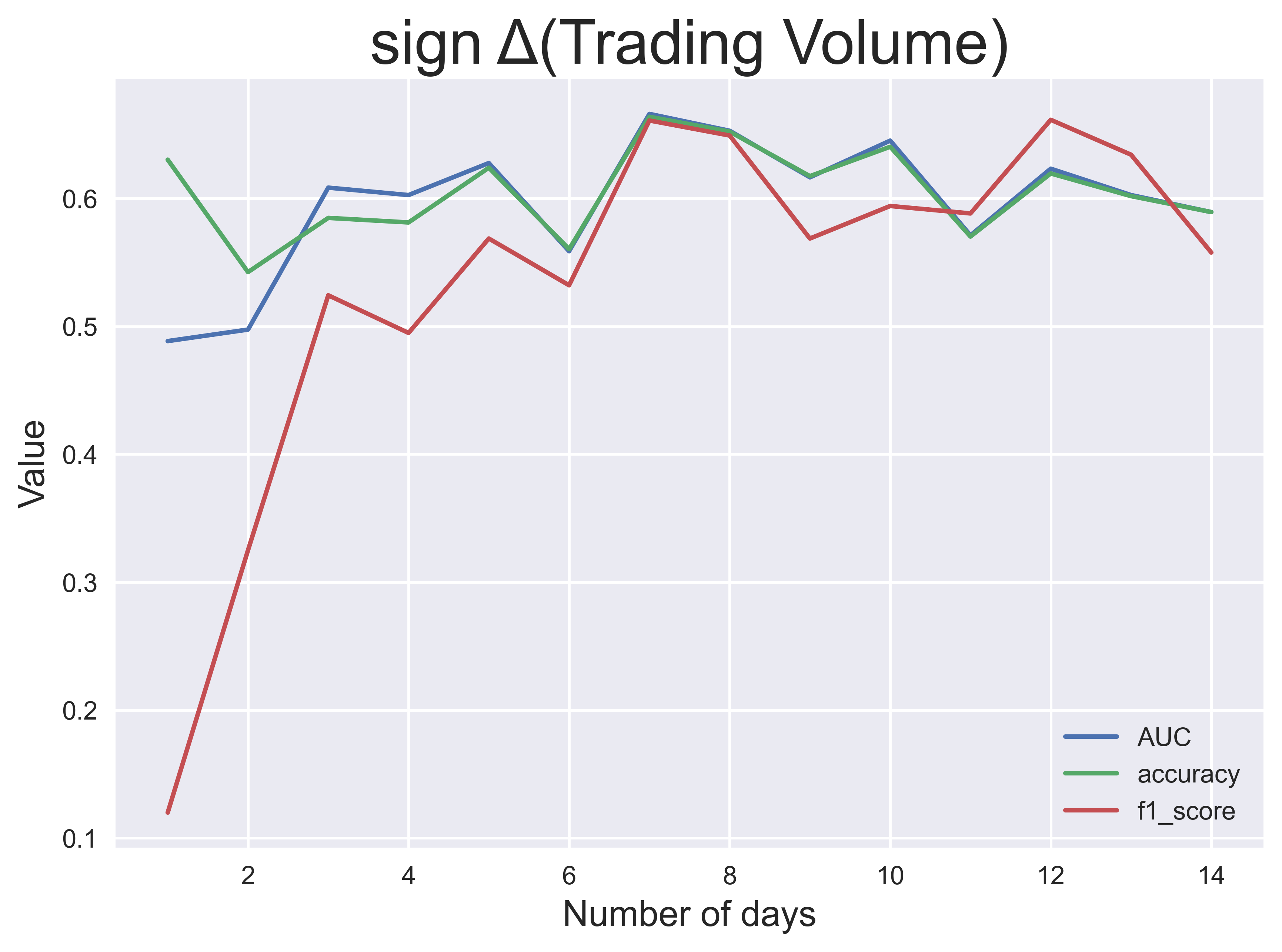
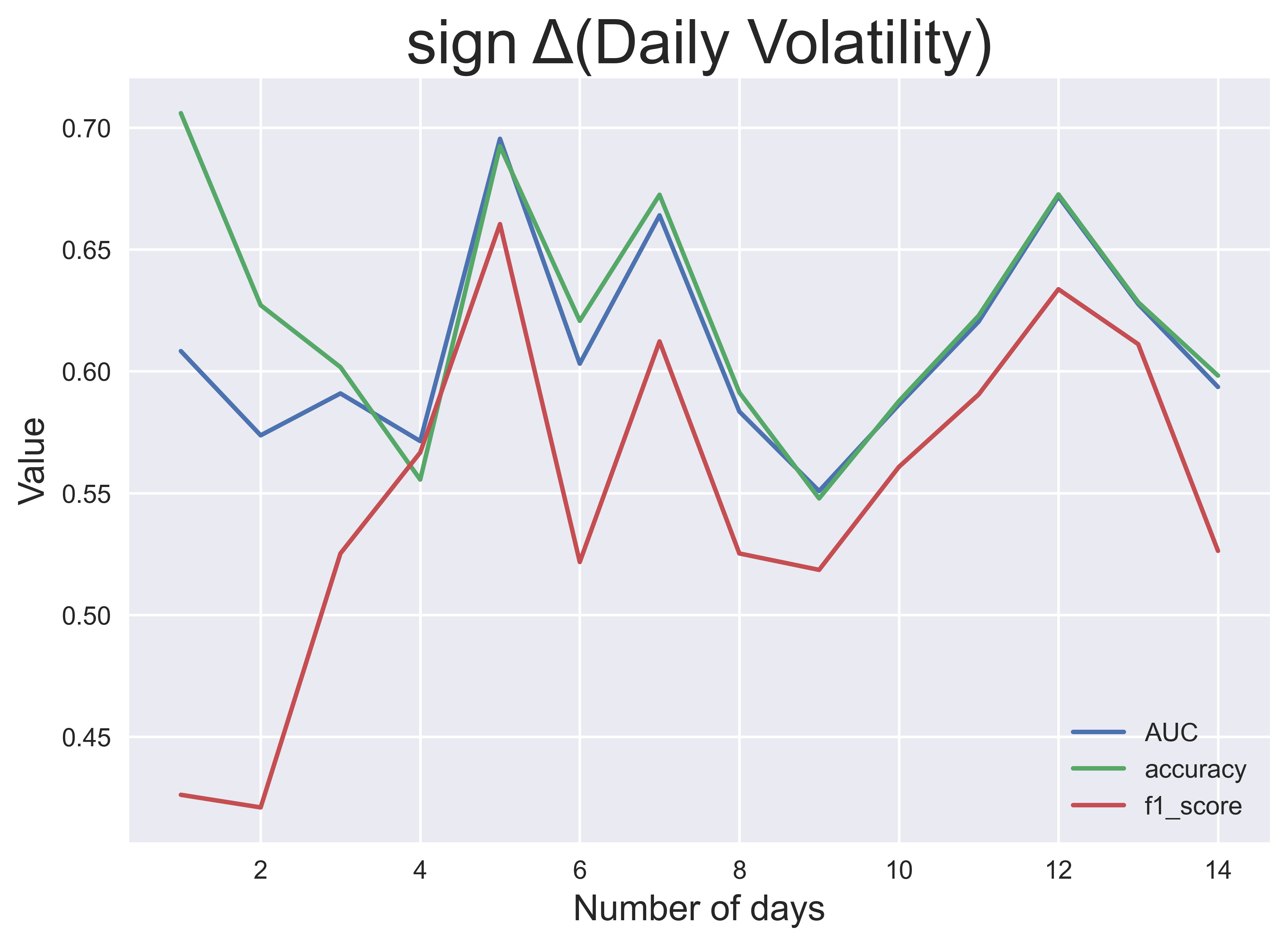
Dieser Prozess wurde für jeweils $n$ bis zu $n=14$ Tage und jedes der vier Zielkennzeichnungen durchgeführt. Die obigen Bilder zeigen die Klassifikationsleistung über $n$, gemessen an drei Leistungskennzahlen: AUC (Fläche unter dem erhaltenen Operationsmerkmal), Klassifizierungsgenauigkeit und $f_1$ score. Aus diesen Ergebnissen stelle ich fest, dass die Leistung der Modelle bei größeren Fenstern im Allgemeinen besser ist, mit Ausnahme der Tagesrendite und der Volatilität.
Erläuterung: Welche Funktionen waren wichtig?
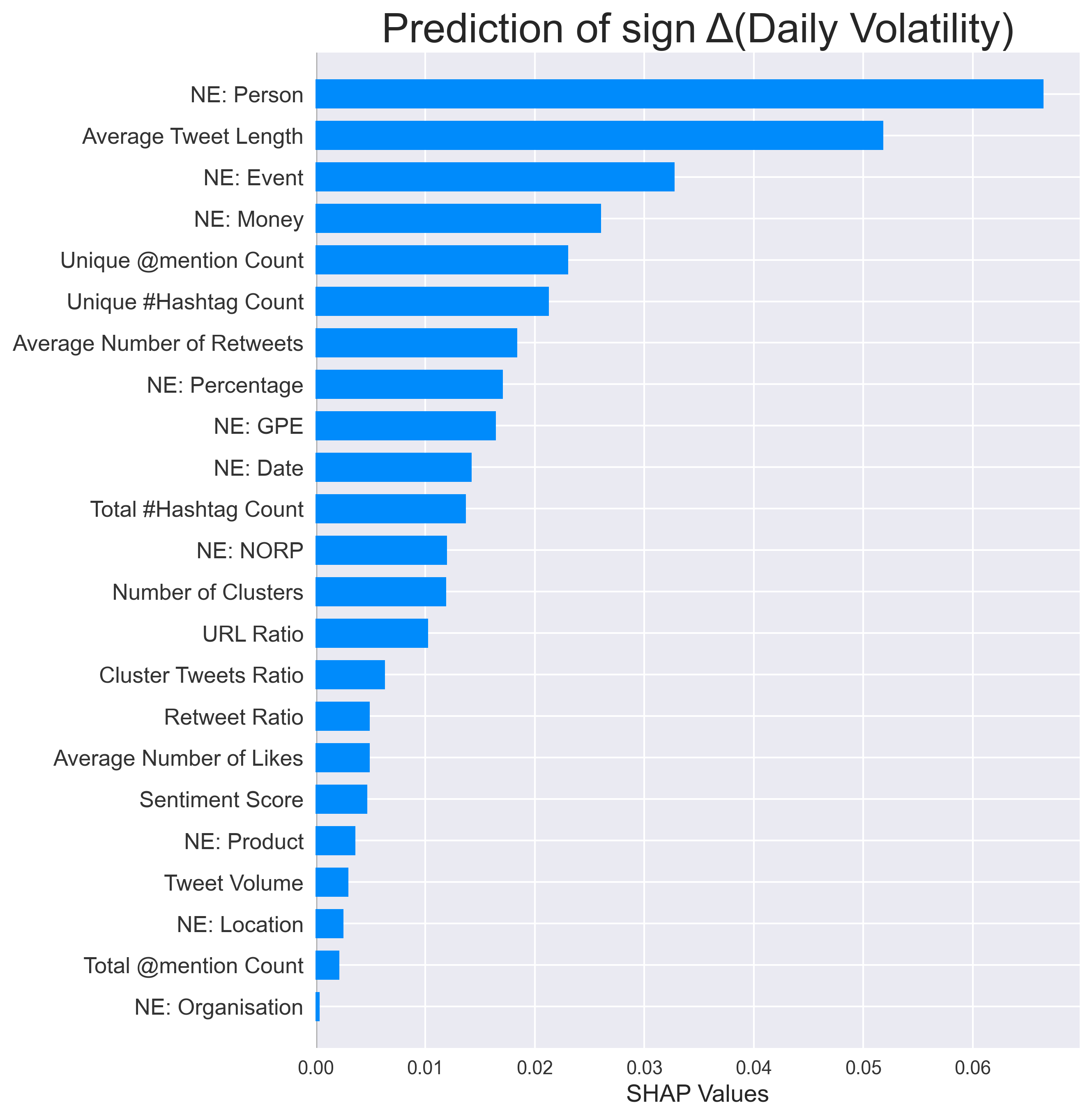
Um zu untersuchen, wie die Features zur Vorhersage beitragen, generiere ich die SHAP-Werte für jeden Klassifikator. SHAP ist ein spieltheoretischer Ansatz zum Verständnis der Auswirkungen, die jedes Merkmal auf ein Modell hat. Insgesamt wirken sich die Merkmale unterschiedlich auf die Schätzung unterschiedlicher Ziele aus. Es wird gezeigt, dass eine Reihe von Merkmalen mehr prädiktive Informationen enthalten als der Stimmungswert. Dieses Ergebnis zeigt uns, dass man viel mehr tun kann als, nur eine Stimmungsanalyse für diesen Datensatz durchzuführen.



Fazit
Auf der Grundlage der obigen Ausführungen legt unsere Analyse nahe, dass der Stimmungswert nicht unbedingt das wichtigste Merkmal für die Modellierung von Aktienkursen ist. Aus diesem Feature-Engineering-Experiment ist es mir gelungen, 23 Merkmale zu erstellen, die für die Bewertung der Performance von Aktien nützlich sein können. Die wichtigste Schlussfolgerung ist, dass es immer weitere Möglichkeiten gibt, unsere Prognosen zu verbessern, seien es zusätzliche Daten, Merkmale, Analysen oder Experimente.
Was kann uns Twitter also wirklich über Aktienkurse sagen? Die einfache Antwort ist viel mehr als nur eine Stimmungsanalyse, wie es die Literatur vorschlägt. Alternativ dazu sollten wir vielleicht auch eine andere Frage stellen: Was können wir mit dieser Erkenntnis noch tun und wie machen wir unsere Studie noch aussagekräftiger? Die Möglichkeiten sind endlos.