
By Kamran Javid
INSIGHTS Research
This year saw the return of in-person research conferences, and the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) was no exception. The event took place in New Orleans, Louisiana from June 19th – 24th (Figure 1). It hosted thousands of researchers from leading academic and industrial institutions (think Google, Meta, Apple, Tesla etc.), and I was fortunate enough to attend the event myself.
Over the years, computer vision has made an insurmountable contribution to Machine Learning (ML) and Artificial Intelligence (AI). From feature detection [1] (analysing an image and decomposing it into “simpler” features, e.g., edges or shapes), Convolutional Neural Networks 2 (neural networks that rely on correlations, usually measured in spatial dimensions, between “nearby” points in an input by applying convolutional filters across the input space), to autonomous driving [3] (self-driving vehicles).
With this in mind and considering that CVPR has the highest h-index (a measure of the impact of a conference, based on some function of citation counts) of any AI-related conference, there’s no doubt that the output of this year’s event will move AI forward. In this blog, I highlight what I think are some of the most interesting papers and ideas to come out of this year’s event and their potential implications for AI and ML in general.

Hyperbolic deep learning
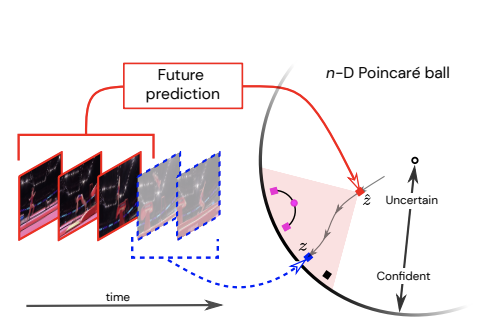
In [4], hyperbolic deep learning is used to classify what will happen next in a video clip, given the previous clip’s frames.
The details of how embedding the training of a machine learning model on a hyperbolic geometry are far beyond the scope of this blog post. However, the essence of the problem is that the model attempts to learn a hierarchy of the possible classifications (outputs, that is, what the next video frame will depict) of a problem and uses the curved surface (Figure 2) of a hyperbolic space to represent these hierarchies and to quantify the uncertainty of a classification. Different levels of the hierarchy are meant to represent the certainty of the model’s prediction.
What this means for AI in general: The idea of training predictive models on a hyperbolic space is completely general to any supervised machine learning task (scenarios where ML is used to generate predictions), and so it will be interesting to see how the concept plays out in other fields.
On a side note, it’s great to see geometry playing a larger part in AI, akin to how Einstein began to form his theory of General Relativity, based on curved spaces and geodesics.
Explainable AI
The fact that explainable AI received a large amount of coverage at CVPR is somewhat telling: it is an area of growing popularity and importance in CV.
The gist of the papers is that the output of a classification algorithm is explained in terms of the inputs to the predictive model (usually a CNN). Of course, in most contexts applicable to these papers, the inputs are images, and so the explanations are formed around “groups” of the inputs, pertaining to features detected in the images by the model (e.g. whiskers on a cat). Another common theme in the explainability papers unsurprisingly was the notion of attention [5] which gives some indication of what inputs “attained more attention” to generate the different outputs. Furthermore, the fact that more ready-to-use open-source tools are being made available rather than just being presented as POCs2, is a breath of fresh air, and hopefully takes some of the weight off the few existing easily-deployable packages such as LIME [6] and SHAP [7].
One paper in particular that caught my eye was [8]. In this paper, instead of trying to explain a model’s prediction using some approximate method after the prediction has been generated, the network’s mathematical formulation is adjusted a priori so that a by-product of the output of the model provides a direct explanation for the prediction in terms of the model’s inputs.

What this means for AI in general: In a field where explanations were not considered pivotal for a long time, it is refreshing to see the topic start to take more of a leading role. Especially as computer vision is applied more and more to real-world scenarios such as medical imaging, and self-driving vehicles, it is crucial that we understand why the blackbox algorithms make the decisions they do. I am confident that this further adoption of explainable AI will continue across different fields in the short-term.
Domain generalisation
Another hot topic in CV currently is domain generalisation. It is well-known that deep learning models perform well during live production when the examples considered in this period are drawn from the same data distribution as what the models were trained on. However, when the models are applied to data distributions different compared to what they were trained on, they often don’t perform as well, as the “patterns” they learned during training and don’t persist for the out of distribution data.
Some interesting papers from CVPR which attempt to address this issue include [9]. In this paper, with the aid of prior knowledge, causal features are learned which are considered to be invariant even across different data distributions. For example, when trying to classify images of different animals, the causal invariant feature would be the profile of the animal, irrespective of the form of the background, which is instead considered as spurious features.

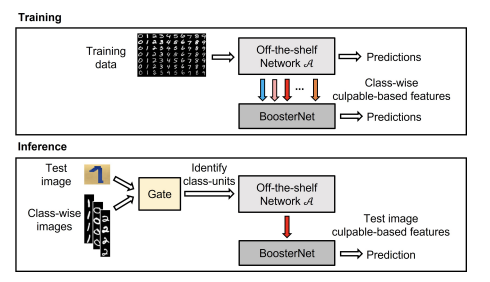
Another paper on this topic from CVPR is [10]. The paper adapts a boosting technique (fitting models to the residuals of the errors of other models’ predictions), applied as an add-on to any deep learning model (Figure 5). In order to improve generalisability, the boosted models are applied to train-cross validation splits of the data during model training, and on a subset of both the most informative and non-informative internal features of the original neural network. During inference, the boosted model used is chosen based on the discrepancy of the input data with the different classes of data used during training. This is measured using a Siamese network (a deep learning model which measures the discrepancy between two sets of inputs). The concept of boosting extends as far back as [11] and is a prominent concept in decision tree-based models.
What this means for AI in general: More focus on domain generalisation is crucial for any scenarios subject to rapidly changing environments, including finance, autonomous driving or weather/natural disaster predicting.
Tail, few-shot and imbalanced data learning
Imbalanced datasets (usually pertaining to the target outputs of the model) are a prominent theme in CV. Think, for example, performing facial recognition on an individual, based on a model trained with only one photo of this individual. Another example in the context of image classification is if a classifier has been trained on a particular set of animals to classify cats and dogs, but then needs to be used to classify another breed of animal (e.g. horses). This extreme case of data imbalance is referred to as zero-shot learning [14].
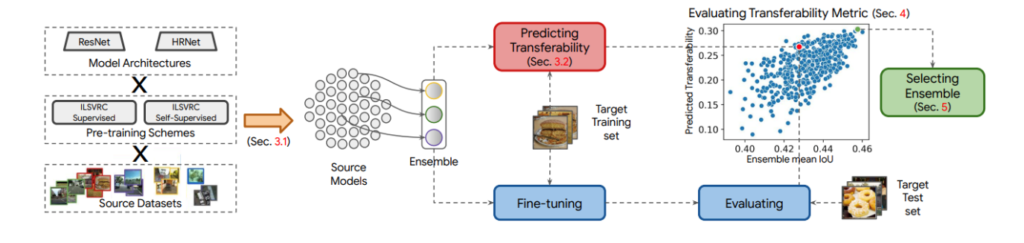
On this theme, an interesting paper from CVPR is [15]. In this paper, a method is proposed for optimally selecting pre-trained models to be applied to a new dataset even if the new data contains classes of images not contained in the pre-trained models, or vice versa. Since fine-tuning all potential pre-trained models on the new data is time-consuming, the paper derives a transferability metric (Figure 6)- an indicator of a model’s performance on the new dataset, which can be calculated by passing the new training data through the candidate models just once. The paper shows that this transferability metric correlates well with true performance on the new test datasets. The final selection of models, as chosen by their transferability metric values, are then fine-tuned (trained) on the training data of the new dataset, and final predictions are generated by ensembling the predictions of these models.
[16] addresses the problem of imbalanced data in a regression (continuous output) setting, (e.g. trying to predict humans’ height). Here the typical loss function used in regression settings (mean squared error) is given a full statistical treatment to derive an adapted loss function which accommodates for any imbalance in data used during model training. The method contains a small additional computational overhead, from the Monte Carlo sampling associated with computing, known as the marginal likelihood/evidence in Bayesian statistics.
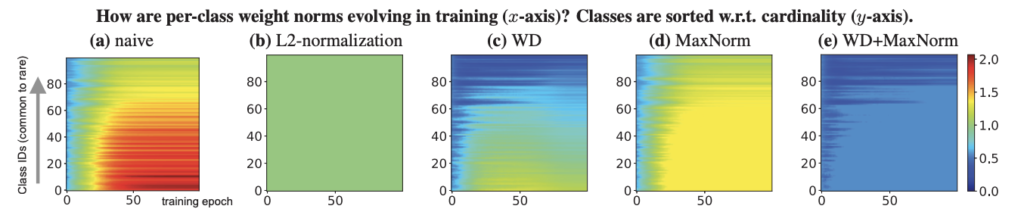
A simple but effective method of dealing with imbalanced datasets is presented in [17]. The authors argue that the weights associated with the last layer of a classification model are imbalanced in norm according to the associated class imbalances (Figure 7). That is, the norm of the weights associated with the components of the probability outputs, in-turn associated with classes which are highly represented in the training data, are much larger than those of the weights associated with underrepresented classes. The authors go on to show that simple regularisation of these weights associated with the output layer of the classification model can counter the class imbalance, and lead to better performance on test sets which are not subject to such imbalanced data.
What does this mean for AI in general: Similar to domain generalisation, research into imbalanced data regimes is crucial for any context which is prone to black swan events.
Final word
One final note from the conference was the rise of transformers [18] in CV. It was interesting to see that they are now very much considered the state-of-the-art deep learning model when applied to CV [19], and a lot of active research is being put into vision transformers [20, 21, 22]. However, it is good to see that work on CNNs in CV is still going on [23], and the two are even being combined [24]. This makes sense given the original transformer model uses something akin to a convolutional filter during one of its operations.
References:
[1] – Lindeberg, T., 1998. Feature detection with automatic scale selection. International journal of computer vision, 30(2), pp.79-116.
[2] – LeCun, Y. and Bengio, Y., 1995. Convolutional networks for images, speech, and time series. The handbook of brain theory and neural networks, 3361(10), p.1995.
[3] – Levinson, J., Askeland, J., Becker, J., Dolson, J., Held, D., Kammel, S., Kolter, J.Z., Langer, D., Pink, O., Pratt, V. and Sokolsky, M., 2011, June. Towards fully autonomous driving: Systems and algorithms. In 2011 IEEE intelligent vehicles symposium (IV) (pp. 163-168). IEEE.
[4] – Surís, D., Liu, R. and Vondrick, C., 2021. Learning the predictability of the future. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12607-12617).
[5] – Bahdanau, D., Cho, K. and Bengio, Y., 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
[6] – Ribeiro, M.T., Singh, S. and Guestrin, C., 2016, August. ” Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1135-1144).
[7] – Lundberg, S.M. and Lee, S.I., 2017. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30.
[8] – Böhle, M., Fritz, M. and Schiele, B., 2022. B-cos Networks: Alignment is All We Need for Interpretability. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10329-10338).
[9] – Wang, R., Yi, M., Chen, Z. and Zhu, S., 2022. Out-of-distribution Generalization with Causal Invariant Transformations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 375-385).
[10] – Bayasi, N., Hamarneh, G. and Garbi, R., 2022. BoosterNet: Improving Domain Generalization of Deep Neural Nets Using Culpability-Ranked Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 538-548).
[11] – Bertinetto, L., Valmadre, J., Henriques, J.F., Vedaldi, A. and Torr, P.H., 2016, October. Fully-convolutional siamese networks for object tracking. In European conference on computer vision (pp. 850-865). Springer, Cham.
[12] – Drucker, H., Cortes, C., Jackel, L.D., LeCun, Y. and Vapnik, V., 1994. Boosting and other ensemble methods. Neural Computation, 6(6), pp.1289-1301.
[13] – Breiman, L., Friedman, J.H., Olshen, R.A. and Stone, C.J., 2017. Classification and regression trees. Routledge.
[14] – Socher, R., Ganjoo, M., Manning, C.D. and Ng, A., 2013. Zero-shot learning through cross-modal transfer. Advances in neural information processing systems, 26.
[15] – Agostinelli, A., Uijlings, J., Mensink, T. and Ferrari, V., 2022. Transferability Metrics for Selecting Source Model Ensembles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7936-7946).
[16] – Ren, J., Zhang, M., Yu, C. and Liu, Z., 2022. Balanced MSE for Imbalanced Visual Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7926-7935).
[17] – Alshammari, S., Wang, Y.X., Ramanan, D. and Kong, S., 2022. Long-tailed recognition via weight balancing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 6897-6907).
[18] – Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł. and Polosukhin, I., 2017. Attention is all you need. Advances in neural information processing systems, 30.
[19] – Khan, S., Naseer, M., Hayat, M., Zamir, S.W., Khan, F.S. and Shah, M., 2021. Transformers in vision: A survey. ACM Computing Surveys (CSUR).
[20] – Sun, T., Lu, C., Zhang, T. and Ling, H., 2022. Safe Self-Refinement for Transformer-based Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7191-7200).
[21] – Lin, S., Xie, H., Wang, B., Yu, K., Chang, X., Liang, X. and Wang, G., 2022. Knowledge Distillation via the Target-aware Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10915-10924).
[22] – Yang, C., Wang, Y., Zhang, J., Zhang, H., Wei, Z., Lin, Z. and Yuille, A., 2022. Lite vision transformer with enhanced self-attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 11998-12008).
[23] – Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T. and Xie, S., 2022. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 11976-11986).
[24] – Guo, J., Han, K., Wu, H., Tang, Y., Chen, X., Wang, Y. and Xu, C., 2022. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12175-12185).