
Isabelle Lorge
INSIGHTS Research
Word soup: working with unstructured data
It is easy to assume that there must be some information in text data which is relevant to market prices. For example, a company’s share price could be negatively affected after a scandal or lawsuit (such as Facebook after Cambridge Analytica), or the price of a commodity changes as a result of environmental and geopolitical events (such as the recently soaring gas prices following last year’s cold winter and increased demand from Asia). Data sources such as news, social media and company’s internal communications have been shown to have some level of correlation with the market. However, extracting such information is far from an easy task. A first issue is that this type of data, unlike traditional financial data, is what is usually called ‘unstructured’ data. This means that it does not come in a readily usable numerical or tabular format i.e., nicely organised rows and columns with headers as you find in an Excel sheet. In addition to this, computers only understand numbers!

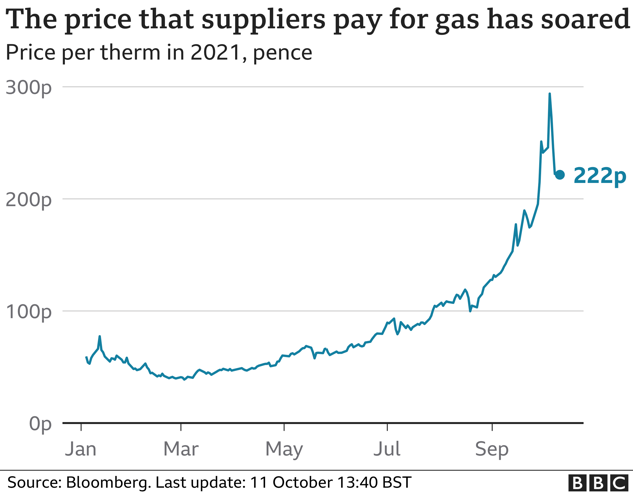
Image Source: https://www.bbc.co.uk/news/business-58090533
Due to this, we need to transform the data in several ways in order to obtain a format which can be used in downstream tasks, such as predicting how the price of a financial instrument is likely to evolve over time. In general, the steps for doing this involve the following pattern:
- Gathering data For example scraping the web, using a news data provider or query a social media’s API, i.e., their user interface.
- Cleaning, or pre-processing the data. Depending on the type of raw data, application and model used there can be as little or as much of this as required. Examples of pre-processing include lowercasing and removing stop words i.e., words which have little meaning content, such as ‘be’, ‘the’, ‘of’, etc.
When the data is scraped from web pages, there can be a lot more work! Think of looking for meaningful content in a pure text version of an article from your favourite news page- without the graphics to help you distinguish between headers, timestamps, social media links, references etc.
- Turning the data into a numerical representation. There are many ways of doing this, with state-of-the-art methods involving models pre-trained on very large amounts of text data which will ‘ingest’ your text and spit out lists of numbers. The choices you make are still very important: Which model? Trained for what task? How do you split your data? How do you combine the results?
- Building a model. Which will use your text data to perform some task.
Let’s have a look at two tasks using text data which are highly relevant to financial applications.
Types vs. tokens: Identifying entities
A first important task when processing textual data involves identifying entities e.g., people such as ‘Steve Jobs’ or organisations such as ‘Microsoft’. This is called Named Entity Recognition (or NER). The way to do this is by gathering relevant data and labelling many instances of it, e.g., labelling ‘Steve Jobs’ as PERSON and ‘Microsoft’ as ORGANISATION, then training a model which will learn which types of words are likely to be instances of either type.
A subsequent step, which can be performed after this, is to link the entity with a reference in the real world through the use of a database. For example, once I have identified that ‘Steve Jobs’ is an entity of the type PERSON, I can go into a database such as Wikipedia to try and find whether there is a PERSON entry with this name. If there were more than one (such as would be the case with, e.g., Amazon– the forest and the company), I will have to use the context of the sentence along with each database entry to try and disambiguate between them by figuring out which is more likely. In the case of Amazon, if the original sentence mentions trees and there is a Wikipedia entry which mentions them too, their numerical representations are likely to be closer, which means Amazon in such a context would get linked to the ‘forest’ entry.
This is a case where some types of pre-processing should not be performed because they could potentially be harmful to recognition. For example, given that upper and lower casing are useful cues, maybe we should avoid lowercasing, e.g., avoid turning ‘Apple’ into ‘apple’.


Image Sources: https://www.popularmechanics.com/science/environment/a28910396/amazon-rainforest-importance/, https://www.ledgerinsights.com/amazon-job-ad-digital-currency-lead-for-payment-acceptance/
In practice, modern systems are now fairly robust to these changes. However, it is still a good habit to keep in mind the type of data we are using and make sure it is processed in a tailored way.
Consider how some types of text, such as news headlines, might confuse systems which rely on casing for entity recognition, e.g.:
“Viacom18 Plans to Adapt More Paramount Titles for India, Sets New Release Date for Aamir Khan’s ‘Forrest Gump’ Adaptation.”
As a human, how do you identify which words are named entities in this sentence? How do we get a computer to do this? These are the type of questions we need to ask ourselves as we try and figure out ways to process the very complex type of data that is language data.
Assessing feelings about assets and events
Another useful task, making use of our numerical representations of text is sentiment analysis or trying to determine whether a piece of text expresses a positive or negative emotion. Traditionally, this has been achieved in financial contexts by using specialised dictionaries (lists of words with a corresponding positive or negative score). However, this is a difficult task to achieve using only lists of words, as sentiment analysis goes beyond the meaning of individual words (consider negations such as ‘This is not a great film’, or sarcastic sentences such as ‘This was a really great film. I absolutely did not fall asleep halfway through’).
The usual way to perform this task is once again to gather relevant data where pieces of text have been labelled as ‘negative’ or ‘positive’ (for example, movie reviews) and train a model to recognise which types of sentences are associated with which emotions. The data used when you are teaching your model should ideally be as close as possible to the data you will be using the model with. For example, if you learn to identify sentiment in movie reviews, you may not perform as well with financial news, as these are fairly different types of text, with different underlying principles and different author populations.
Another thing to keep in mind is that ‘sentiment analysis’ generally means analysing the overall sentiment expressed in a piece of text. It does not necessarily say anything about the valence (emotional score) of an event. For example, the event of a zoo closing may be positive from the point of view of an author worried about animal rights, but negative from the point of view of the zoo staff. Similarly, the event of a hostile takeover, such as that of Cadbury by Kraft Foods in 2009, may carry positive emotions for the latter and negative emotions for the former, but a piece of text will only have one sentiment score.
Even with state-of-the-art models, performance in this task is still far from perfect, as they still struggle with negation and sarcasm, as well as displaying worrying consistency issues and bias e.g., predicted sentiment changing when swapping names or locations in the text, which should not happen. This is partially due to the way these models are trained. Being left to figure out which language predicts sentiment without much guidance, they may pick up on correlations which we would consider meaningless e.g., every instance of text including Brazil that the model received happened to be negative, therefore Brazil will bias the prediction towards negative sentiment.
Aligning cause and effects
Finally, suppose you have performed the previous two tasks, i.e., you have identified which assets are referred to in your text data, and which sentiment is expressed each time. How do you use this in relation to the market? How do you know whether this sentiment will impact prices, and when?
This is probably the trickiest bit. While sentiment extracted from news and other similar sources does correlate to some extent with the market, this has often been demonstrated by aggregating over many years of data, using high quality curated data or manually selecting relevant news. What is more, there are some effects which make the task even harder. First, it has been shown that the market starts to react to a piece of news sometimes up to two weeks before it is published (as the content of announcements will often be common knowledge before they are made official). Second, different types of news and media content will have different lags and timelines in how they affect the market. For example, the market does not react in the same way to positive and negative events. Lastly, most text data gathered is likely to be irrelevant and have no impact whatsoever. This makes it very difficult to train a model, as it will have to work with a very low information to signal ratio, just like is the case for the price data! In fact, the use of noisy language data on top of already-noisy financial data is what makes this a very difficult problem to solve indeed.